

TechnologyDecember 4, 2020
Distributed I/O and control builds IIoT from edge to cloud

Next generation digital I/O and more distributed global architectures are enabling connectivity to the cloud for sensors and actuators, and for the I/O systems and controllers linked to them. These edge-to-cloud architectures depend on options at the edge for acquiring, securing, storing and processing field data.
Digital transformation along with the Internet of Things (IoT) or Industrial IoT (IIoT), are familiar concepts to almost anyone working in a role involving industrial automation. These initiatives involve ever smarter devices communicating progressively closer to the “edge,” perhaps connected to an internet “cloud,” or even through some kind of intermediate “fog.” Even if we consolidate these terms under the umbrella of IIoT, for most folks a simple question remains: what is the goal of the IIoT?
Simply put, end users would like the IIoT to create a cohesive system of devices and applications able to share data seamlessly across machines, sites, and the enterprise to help optimize production and discover new cost-saving opportunities. Sharing process data has long been a goal of industrial automation, but traditional operational technology (OT) architectures are poor at scaling, priced prohibitively, and demand complex configuration and support. So what is changing to achieve this more ambitious goal?
Much as consumer hardware and software technologies have shifted to improve ease-of-use and connectivity, industrial products and methods are following the same trend. By adopting information technology (IT) capabilities, they are making it easier to connect industrial equipment with computer networks, software, and services, both on premises and in the cloud.
Up and down the architecture
Industrial automation architectures generally address data processing from a hierarchical perspective, as with the classic Purdue model. One good feature of this hierarchy is the clarity it provides with regard to where data can originate, be stored, undergo processing, and be delivered.
However, the task of transporting data and processing it in context is often quite difficult, because so many layers of equipment are required to connect devices and applications.
For example, the illustration above shows a traditional method of acquiring temperature data from facility equipment and moving it to a back-end client, like a database.
The lowest level of the automation architecture is made up of the physical devices residing on process and machinery equipment: sensors, valve actuators, motor starters, and so on. These are connected to the I/O points of control system programmable logic controllers (PLCs) and human-machine interfaces (HMIs), both of which are well suited for local control but less useful for advanced calculations and data processing.
However, using industrial communications protocols, these low-level devices can respond to data requests from upstream supervisory control and data acquisition (SCADA) systems where it might be historized or made available to corporate-level analytical software. Sharing data within multi-vendor systems, however, often requires additional middleware, such as OPC device drivers, to translate the various industrial protocols.
More advanced site manufacturing execution system (MES) and overall enterprise resource planning (ERP) software also reside at higher levels of the architecture, hosted on PCs or servers on site or in the cloud, where the cloud is defined as large-scale, internet-based, shared computing and storage.
Information generally flows up to higher levels to be analyzed and used to optimize operations, but the middle layers are required in order to interpret, translate, filter, and format the raw data produced by low-level devices and protocols.
Since these low-level devices typically lack protection against cyber-intrusion, a clear division must also be maintained between high-level systems exposed to external networks and low-level systems. Developments over the past decade are significantly altering this traditional hierarchy, flattening and simplifying it to a great extent.
Spanning edge, fog and cloud
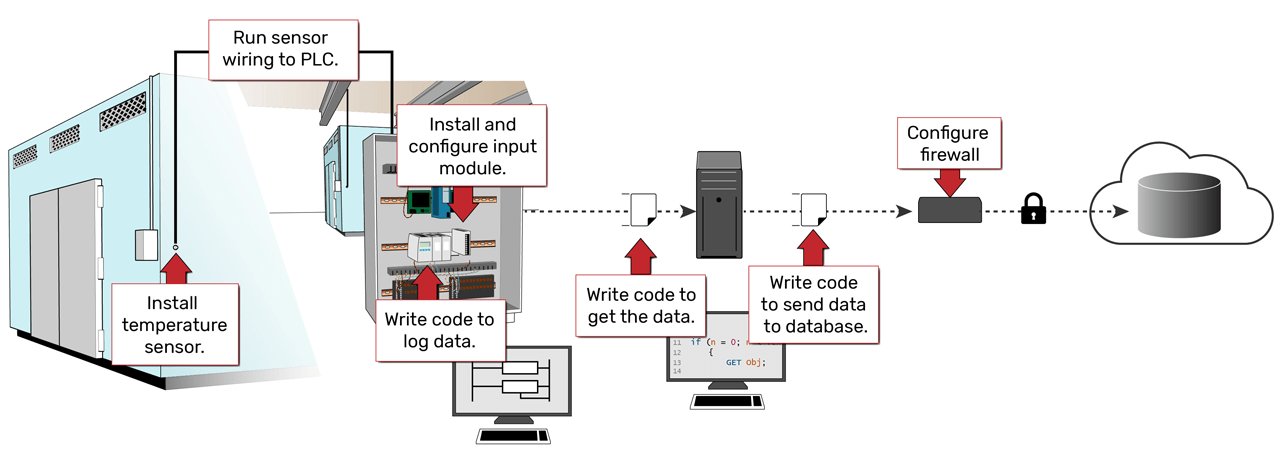
Traditional data acquisition methods require configuring and maintaining many layers in a hierarchy of hardware and software.
A hierarchical approach was necessary when computing capability, network bandwidth, and security features were much less available. Each step up the hierarchy from a basic hardwired sensor to cloud computing systems was required to access greater computing and networking resources. It also clearly delineated the security measures networks required around unsecured field equipment.
Today, the relationship has changed because sensors and other edge devices are far more capable, with some of them including processing and communications abilities similar to a PC. Security protections like embedded firewalls are also becoming a standard feature, allowing each device to act as a peer on the network instead of passively listening and responding to high-level systems.
The architecture is evolving to become flatter and more distributed, as in the image below, which illustrates the same data acquisition scenario but replaces several layers with a low-level device capable of sending data directly to its destination.
The edge, made up of low-level networks, is still a critical source of data, and the cloud is still a valuable resource for heavyweight computing. However, the resources in between, especially at the site level, are becoming a blend of data-generating devices and data-processing infrastructure.
This fuzzy middle ground earns the name fog, because it is akin to a widespread, pervasive, and middleweight cloud.
Many other factors besides advancing technology are driving this shift to a flatter architecture. The most straightforward motivation is to balance computing and networking demands between the edge and higher-level systems. Edge computing offloads central processing, preserves data fidelity, improves local responsiveness and security, and increases data transfer efficiency to the cloud.
Ultimately, however, this edge-to-cloud architecture depends on having new options at the edge for acquiring, securing, storing, and processing field data.
Distributed I/O evolution
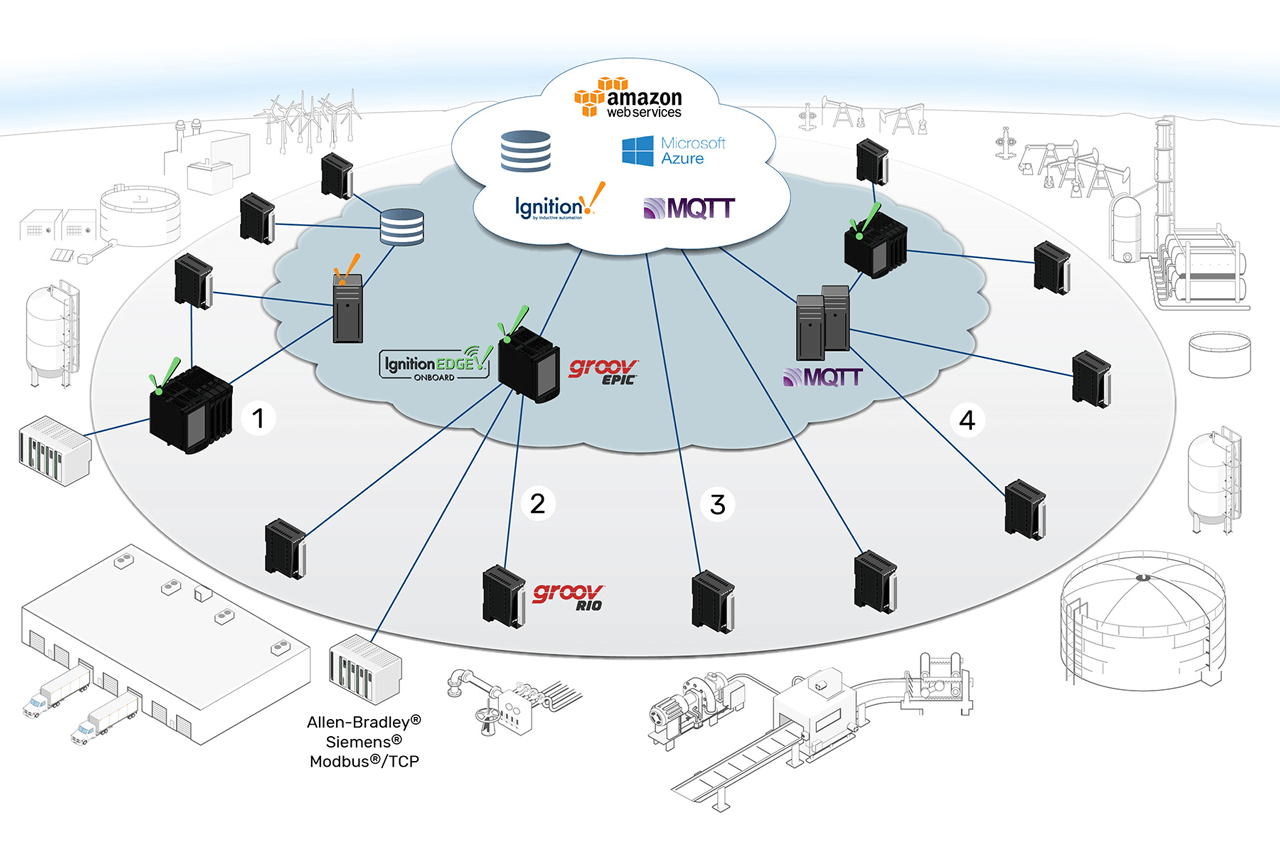
Edge controllers and edge I/O enable new information architectures in which devices share data locally and across the organization, through edge, fog, and cloud.
Field data can be raw I/O points connected at the edge or derived calculation values. Either way, the problem with traditional architectures is the amount of work it takes to design, physically connect, configure, digitally map, communicate, and then maintain these data points. Adding even one point at a later date may require revisiting all these steps.
To create more scalable, distributed systems, some vendors are making it possible to bypass these layers between the real world and intermediate or top-level analytics systems.
With enough computing power, all the necessary software for enabling communications can be embedded directly in an I/O device. Instead of requiring a controller to configure, poll, and communicate I/O data to higher levels, I/O devices can transmit information on their own.
This kind of edge data processing is becoming possible also due to a proliferation of IIoT tools, for example:
MQTT with Sparkplug B
A secure, lightweight, open-source publish-subscribe communications protocol designed for machine-to-machine communications, with a data payload designed for mission-critical industrial applications
OPC UA
A platform-independent OPC specification, useful for machine-to-machine communication with legacy devices
Node-RED
A low-code, open-source IoT programming language for managing data transfer across many devices, protocols, web services, and databases
Today’s smart remote I/O, also known as edge I/O, takes advantage of these technologies and combines them with standard IT protocols like TLS (transport layer security) encryption, VPN (virtual private networking) for secure remote connection, and DHCP (dynamic host configuration protocol) for automatic addressing. Rather than requiring layers of supporting middleware, edge I/O devices are first-class participants in distributed systems.
Another obstacle to scalability for IIoT systems based on classic I/O hardware is the work required to provide power, network connections, and the right I/O module types. To address these issues, vendors are taking advantage of new technologies to make distributed I/O more feasible and flexible.
Power plus networking
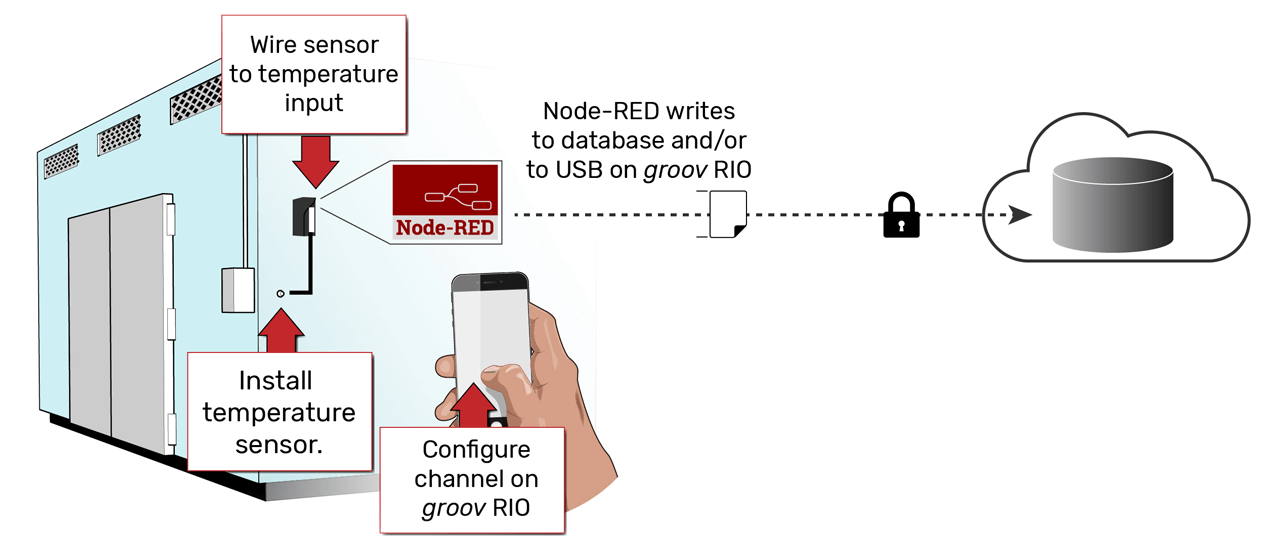
Modern edge devices, such as the Opto 22 groov RIO, flatten and simplify the architecture required to connect field I/O signals to business and control applications.
One example is power over Ethernet (PoE) capability, which uses an Ethernet network cable to simultaneously supply low-voltage power and network connectivity.
When PoE is embedded into an edge I/O device, it can even supply I/O power, simplifying electrical panel design and saving money on additional components and labor.
Flexible I/O
To make it easier for designers to specify the right I/O interface types, some new I/O devices also offer more flexible configuration, like mixed and multi-function I/O channels. These provide extensive options to mix and match I/O signal types as needed on one device, reducing front-end engineering work and spares management.
The combination of these features within edge I/O devices makes it possible for implementers to easily add I/O points anywhere they are needed, starting with a few points and scaling up as much as necessary at any time. Wiring needs are minimized, so long as networking infrastructure is accessible.
For more comprehensive integration, control, and calculation, any number of edge controllers can also be integrated.
Edge controllers bring it together

Opto 22 Groov RIO Edge Controller
As with traditional I/O hardware, traditional industrial controllers are limited in scope and require intermediary systems in order to connect process data to the rest of the organization. Like edge I/O, modern edge programmable industrial controllers (EPICs) leverage new technologies to assimilate more automation functions than previous generations could.
With industrially hardened components, secure networking options, multi-language programming, and multi-core processing, edge controllers can deliver traditional real-time I/O control while also hosting communications, visualization, and even database servers.
In the case of IIoT applications, edge controllers can use this flexibility to communicate with an array of data producers, transform their data in meaningful ways, and deliver it securely to data consumers.
Edge controllers combine sensing and control of traditional I/O, intelligent device fieldbus protocols, and modern edge I/O. They can also host OPC UA servers like Ignition Edge to communicate with a variety of networked devices, making them uniquely efficient at bridging disparate automation networks.
Then, with support for IT-compatible MQTT and REST interfaces and a variety of networking options, EPICs can securely connect OT networks to IT systems while reducing the layers of middleware required to do so. The combination of edge I/O and edge control leads to a new distributed data architecture.
New system architecture options
So what new architectural possibilities are available to industrial automation designers using modern edge I/O and edge controllers?
With edge devices making local data available to computing resources at the edge and at higher organizational levels, the logical hierarchy can be flattened even as the geographical distribution is expanded.
Here you can see some examples of new information architectures that are becoming possible for use in places like remote equipment installations, commercial facilities, campuses, laboratories, and industrial plants.
Shared infrastructure processing
Where field signals are distributed over large geographic areas or multiple sites, edge devices can facilitate data transmission to networked applications and databases, improving the efficiency and security of local infrastructure or replacing high-maintenance middleware such as Windows PCs.
For example, area 1 in the image above shows edge I/O (groov RIO) placed at multiple remote sites with an edge controller (groov EPIC) at another site integrating data from existing PLCs. Two of the edge I/O modules are sourcing, processing, and communicating field data directly into a central corporate database, using Node-RED. The EPIC and other edge I/O exchange data for local control while also transmitting data to a central SCADA over MQTT. Data processing is distributed throughout the edge network, allowing central systems to ingest data more efficiently.
The combination of smart hardware and software closes the gap between OT and IT systems, creating a unified data network that is scalable and centrally managed.
Legacy device integration
Edge I/O can form a basic data processing fabric for existing equipment I/O in brownfield sites and work in combination with more powerful edge controllers and gateways using OPC UA to integrate data from legacy RTUs, PLCs, and PACs. This approach improves security and connectivity without interfering with existing control systems.
The example in area 2 demonstrates this. An edge controller acts as a secure gateway for legacy devices, allowing them to interact with cloud-hosted IoT platforms, SCADA, or MQTT clients while protecting them against unauthorized access from external networks. At the same time, edge I/O is used to integrate facility equipment (pumps, blowers, temperature sensors) and new equipment skids into the same network. The groov EPIC may control the groov RIO modules, aggregate and buffer their data in an embedded database, or simply transmit data to external systems.
Direct-to-cloud I/O network
Engineers can also design simple, flat, data processing networks using only edge I/O devices (without controllers or gateways), expanding as needed to monitor additional field signals. A distributed I/O system like this can process and report data directly to cloud-based supervisory systems, predictive maintenance databases, or MQTT brokers.
Area 3 shows groov RIO modules reporting data from the factory directly to the cloud, via Node-RED or MQTT. There’s no need for intermediary control hardware, because each module provides configurable firewall and data encryption settings as well as a data processing engine to combine, filter, and format data. Since each edge I/O module is independent, the network can grow incrementally, reducing capital project expenditures required to integrate new equipment.
Many-to-many MQTT infrastructure
Edge devices with embedded MQTT clients can publish field data directly to a shared MQTT broker/server or redundant MQTT server group located anywhere the network reaches: on premises, in the cloud, or as part of regional fog computing resources. The broker can then manage subscribers to that data—any number of interested network clients across the organization, including control systems, web services, and other edge devices.
Area 4 shows this architecture. Both groov RIO and groov EPIC have embedded MQTT clients, allowing any of the other architectures to be combined into an efficient data-sharing network. Two edge I/O modules in this example are publishing to a regional server group.
The other two are communicating with an edge controller at another site, which is using the edge modules as distributed I/O and publishing their data into the MQTT network. Once data is published to the broker, devices and services that need that data can subscribe to it from wherever they are on the network.
Seamless connectivity
Seamless connectivity is now a reality, thanks to technologies that make ubiquitous data exchange possible. New hardware and software products enable interconnectivity among physical locations in the field, at the local control room, in the front office, across geographic regions, and up to global data centers.
Distributed edge I/O, edge controllers, and associated networking technologies support data transfer through the edge, fog, and cloud portions of an industrial architecture. Using this approach, you can erase the former boundaries between IT and OT domains and get the data you need to optimize operations.
Josh Eastburn, Director of Technical Marketing, Opto 22.