

TechnologyNovember 1, 2022
How all protocols fail at data access interoperability
If you are interested in being challenged to fundamentally rethink how an enterprise-wide Data Access system should be architected, you have come to the right place. Matthew Parris, Senior Manager, Advanced Manufacturing – Test Systems for GE Appliances, shares his experiences and ideas for moving ahead.
Note from the Author – I have bad news: most industrial interoperability discussions include empty promises. However, I also have good news: the reason for the empty promises is not a technological problem. Even better news: interoperability is a problem that has already been solved once, and those concepts can be reused to solve today’s problems.

If you are looking for a short article that will gloss over vague concepts using a few buzzwords sprinkled throughout, save your time by not reading this article. However, if you are interested in being challenged to fundamentally rethink how an enterprise-wide Data Access system should be architected, you have come to the right place. This article is written for those disappointed by the lack of available products that enable data access interoperability within the manufacturing industry. It is mainly targeted to those interested in turning the paradigm upside-down to move the industry in the right direction.
When authoring this article, I considered whether the content should be delivered as a series of small and manageable articles or whether it should be a comprehensive and cohesive tome. Whereas our modern sensibilities prefer the convenience of fast food with small portions individually wrapped and delivered immediately, I am presenting you with a ribeye steak.
So, if you only have the time for fast food or your pallet will not appreciate a steak, do not read this article; its length will not disappoint a publication with “Book” in its name. When you are ready, however, schedule an hour, pour a pint of New Castle or a stein of Märzen, and have a ribeye steak. Take the time to digest, then decide what your role will be to improve the manufacturing industry.
IIoT: Real-time Data Access
Most take for granted how many mechanisms must work correctly to receive information through computer networks. However, supplying information in scalable ways through equipment across the globe is only possible through interoperability, primarily achieved through a commercial market coalesced around a few well-known standards. As various parts of a technology stack become standardized through commercial products, the quicker “things” can be connected and integrated at scale.
Take the familiar example of web browsing, where a modem is a gateway for the internet. After purchasing a PC, it is brought home, and the benefits of standardization are immediate. First, the out-of-the-box PC likely has an Ethernet port; if not, one can be readily added from any third-party company. After connecting the PC to the internet modem, it gets an IP address through the Dynamic Host Configuration Protocol (DHCP) and discovers its network gateway. Then it discovers what its Domain Name System (DNS) server is and starts accessing a broad range of information from across the globe. All these mechanisms are automatically activated through a single gateway; for most users, it is a technology equivalent to magic.
Like the plug-and-play experience of web browsing, manufacturing seeks to automate the integration of equipment and applications, so instead of humans connecting things manually, they invest their time towards complex challenges. However, anyone participating in Industry 4.0 knows that standardization is still ongoing. In many ways, it is only beginning, and products within the marketplace have yet to pick a standard set of technologies.
The Industrial Internet of Things (IIoT) includes many services and functions. Still, the focus of this article is Real-time Data Access, also often referred to as equipment or process telemetry. This type of data is typically categorized as time-series data, non-transactional, in the form of true-false, numbers, or text. Visualizing or measuring what is occurring on the plant floor is usually the first baby step in digital transformation. This article focuses on the most straightforward use case of IIoT—Data Access—to demonstrate the significance of the interoperability gap. IIoT presents an enormous challenge for manufacturers, and even attempting to tackle this aspect of accessing data from the plant floor is enough to halt some Digital Transformation initiatives. If the amount of market confusion on just this one IIoT topic is any indication, then a long road awaits manufacturers embarking on their journey.
The content below first outlines a framework in which data access technologies can be assessed. Then, it compares existing Data Access technologies from the perspective of this new Data Access framework. Later, client-server applications are contrasted with publish-subscribe applications when deploying an enterprise-wide communication infrastructure. Finally, this article identifies the most significant standardization gap in data access, halting efforts of manufacturers to deploy interoperable systems.
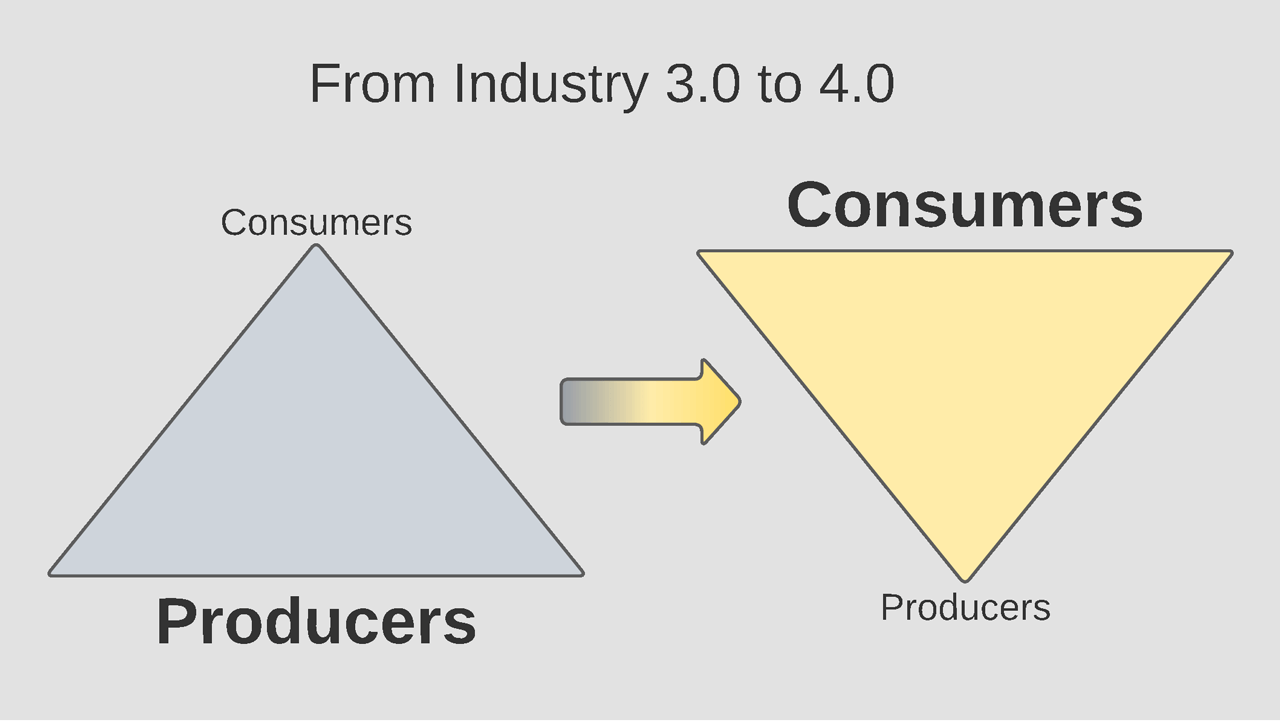
Industry 3.0: Decoupling Physical Location
Forty years ago, battles raged regarding which low-level protocols should dominate the market, such as X-25, FrameRelay, Thicknet, ARCNET, Token Ring, Fiber Distributed Data Interface (FDDI), and Ethernet. These technologies sought to ease the burden of connecting consumer applications to data sources. Unfortunately, many times, connectivity was constrained by the physical locations of each.
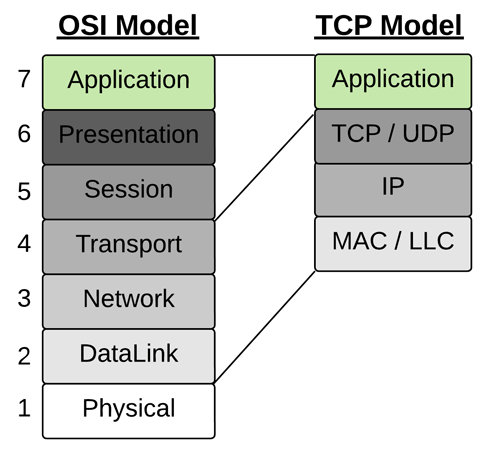
As more technologies and protocols were developed, the seven-layer Open Systems Interconnection (OSI) Model was published in 1984 to coordinate interoperability between disparate systems. Today’s network architectures still reference the OSI model by labeling network equipment as Layer-2 or Layer-3. The OSI model, however, is less relevant than it once was; the protocols used within today’s network stacks fit outside the seven-layer model–either a protocol spans multiple layers, or one layer implements numerous protocols. Competing with OSI, the TCP Model reduced the number of layers to four and used specific protocols at three of the layers. This specificity focused the market on producing products that would interoperate out of the box.
While the TCP Model adds complication and abstraction compared to applications that access devices directly through physical interfaces, embedded protocol stacks and operating systems have shielded applications from this complexity. Furthermore, given the ubiquity of the TCP Model, applications have the benefit of assuming standard connectivity methods regardless of each device’s location. When developing applications before the TCP Model, the market expended energy on learning about all the possible connectivity options and optimizing the best technology for a given solution. After TCP Model became the standard, the market refocused its energies on developing standard application protocols such as HTTP, Modbus, and OPC Classic on top of a consistent network infrastructure. The efficacy of providing the commercial market with a narrow and capable technology stack is undoubtedly proven by today’s internet ecosystem, comprised of many Original Equipment Manufacturers (OEMs) and network architects who design and manage the many components comprising the worldwide web. This global network is only possible with the market coalescing around specific standards.
The Data Access Model Explained
While powering worldwide connectivity, the TCP Model does not detail communication protocols or information encodings required for consumers and producers. IIoT initiatives are not primarily concerned with the physical network connections, how the LANs are segmented, which routes must be taken, or how to maintain connectivity reliability; all these capabilities are assumed to exist already. The discussions regarding IIoT architectures primarily target the only layer not standardized by the TCP Model: its Application Layer. In place of the TCP Model, OEMs, system integrators, and end users need a new framework to improve the discourse regarding product capability and Data Access strategies– a model that reveals the interoperability intricacies between consumers and producers.
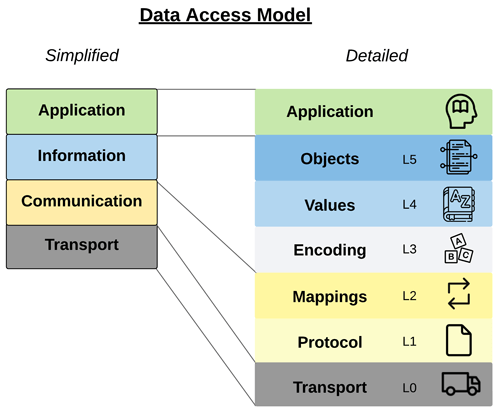
Just as the TCP Model compresses all the IIoT efforts into a single Application Layer, a new framework, The Data Access Model, compresses all the network infrastructure into a single Transport Layer.
A Communication Layer sits above the Transport Layer and handles how data from TCP/UDP moves between producers and consumers. An Information Layer above the Communication Layer specifies the information formats. Finally, on top of the Information Layer sits the Application Layer, which is the business justification for embarking on the IIoT journey in the first place.
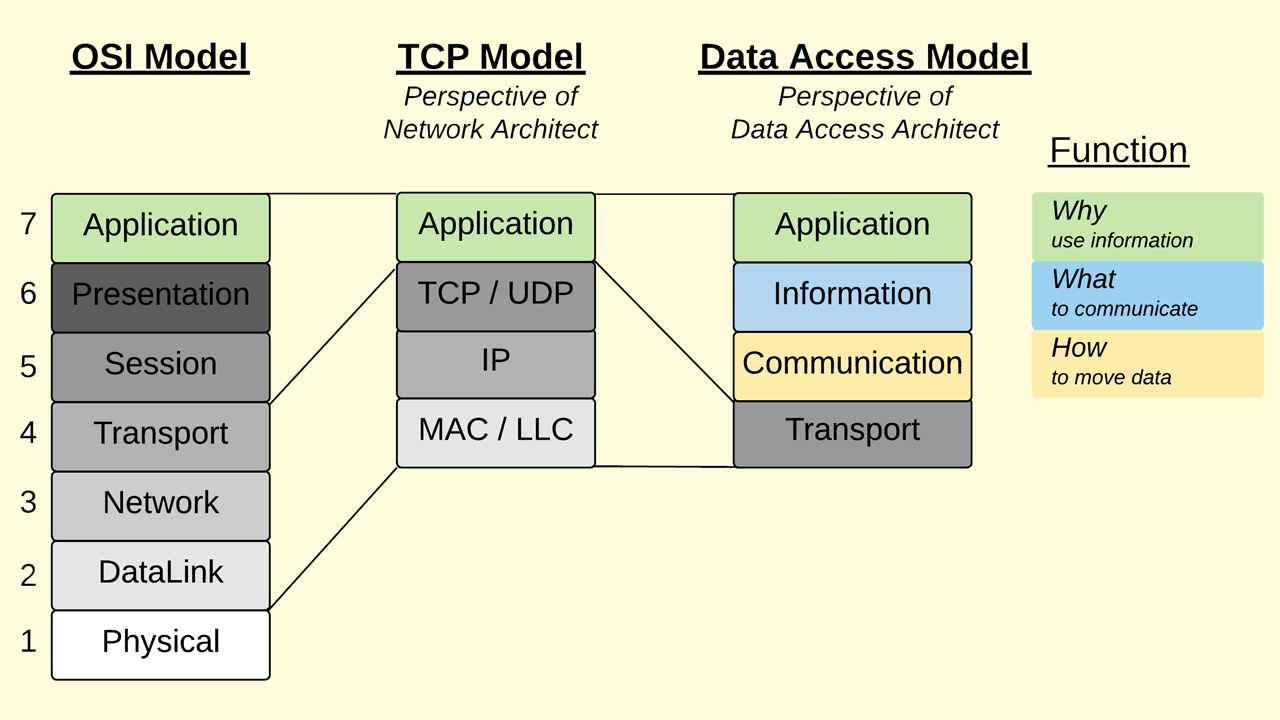
The simplified view of the Data Access Model must be expanded into more layers to expose how consumers and producers need standard definitions to eliminate custom integrations. For example, the Communication Layer defines the communication protocol, but those having integrated systems know that more than the protocol is needed for interoperability. In addition, there are many ways a protocol can be used, so a Mappings layer is necessary to standardize how to use a given communication protocol by defining what functions are within the scope of the application and what protocol options are declared mandatory. Similarly, the Information Layer must be expanded to detail the many ways to represent data through various encoding schemes, values, and object definitions.
The diagram shows typical Data Access applications within the model to understand how this model is applied in the real world. For the web browser application, Communication Layer is handled by the Hypertext Transfer Protocol (HTTP), Information Layer is implemented by Hypertext Markup Language (HTML) and encoded by ASCII Text. The tech stack here is narrow and well-defined, eliminating multiple options within each layer where no custom definitions exist, allowing customization with the content itself. This standard has enabled wide-scale interoperability for the internet by reducing the number of protocols engineers must learn and eliminating code that would have been written had more protocols been allowed as options.
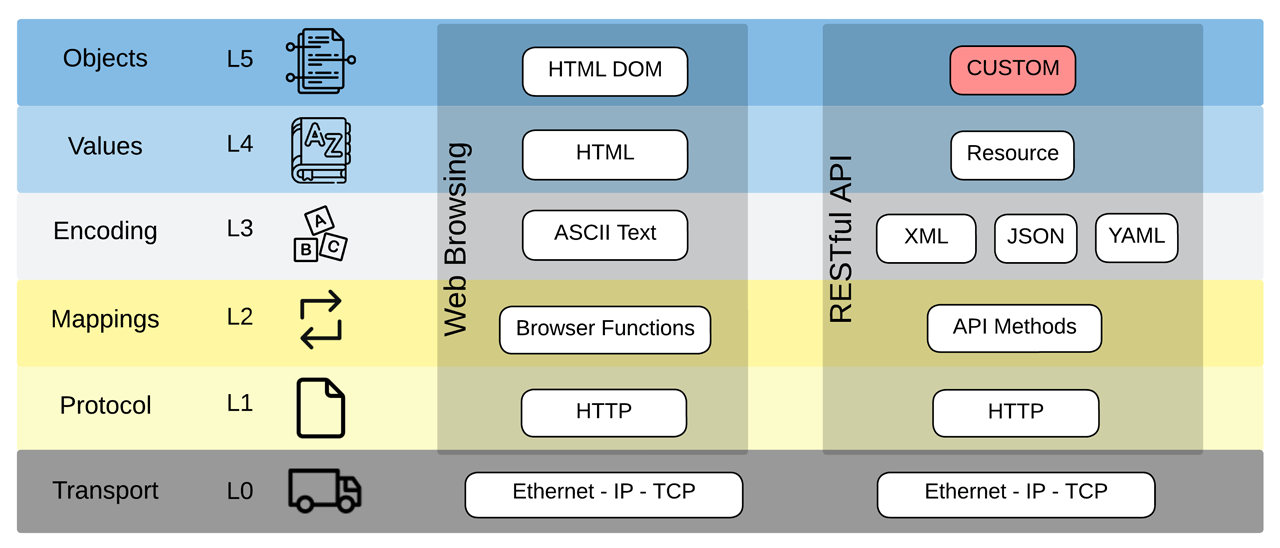
A RESTful Application Programming Interface (API) is another standard method of exchanging information and was designed for flexibility. Compared to Web Browsing, the extra flexibility complicates interoperability between consumers and producers. While HTTP is a widespread communication protocol and is primarily assumed to be used by producers, many choices remain for the levels above, such as encoding or value types. To achieve interoperability, one of two scenarios must take place. First, consumer applications must be developed to accommodate all possible encoding and value schemes. Alternatively, an integrator must determine what encoding scheme a producer uses and then closely evaluate the capabilities of the target consumer application and, if necessary, develop a translation service to enable compatibility. Additionally, while APIs only define a single data type — called a “Resource” — the Object Definition is completely custom. Undefined objects favor flexibility at the expense of higher integration efforts learning about the custom model, and then determining how best to map it to whatever object definition already exists within the enterprise.
How OPC UA and MQTT Prevent Interoperability
One of the many goals of Industry 4.0 is to eliminate the integration cost when incorporating new producers or consumers within the enterprise. Simplifying integration is achieved primarily through products implementing a handful of well-known standards at the Communication and Information layers. OEMs solving this problem may advertise their products as supporting “OPC UA” or MQTT.” Similarly, end users may specify equipment to comply with “MQTT” or “OPC UA.” Are these two terms, however, enough to achieve interoperability?
MQTT has become a popular choice for systems implementing “provide data once; distribute everywhere” architectures. Defined in 1999 towards the tail-end of the protocol wars, MQTT defined a lightweight alternative to traditional client-server connectivity for distributed oil wells constrained by expensive satellite bandwidth. MQTT reduces bandwidth by moving from a conventional poll-response behavior to an event-based behavior where a consumer waits for changed data. In addition, defining devices and equipment with MQTT has reduced the cost of integration since the consumer application can have a single connection regardless of the number of producers and, through wildcard subscriptions, can automatically discover new data as it appears. While invented as an Industrial Protocol, it remained largely unknown until around 2011, when IT-based companies began learning its inherent scalability and deployed the technology within popular, consumer-facing applications. Ironically, the protocol’s popularity within the IT space was needed to provide a compelling reason to begin deploying an OT protocol within the plant floor.
The OPC Foundation released its first OPC UA specification in 2006, which featured Data Access among many other connectivity functions. Products began implementing OPC UA to transform existing connections with benefits such as enabling non-Windows devices, browsable address spaces with standard datatype definitions, and long-polling mechanisms with dead-band filter criteria. OPC UA became popular among manufacturers because it upgraded existing client-server paradigms established from the original 1996 OPC specification. As publish-subscribe protocols increased in popularity, PubSub connectivity was added to the specification in 2018, including broker-less protocols (Ethernet and UDP) and brokered protocols (AMQP and MQTT). Continuing its goal of interoperability, the OPC Foundation defined standard object types through companion specifications, each of which utilizes the core data definitions to construct standard object definitions.
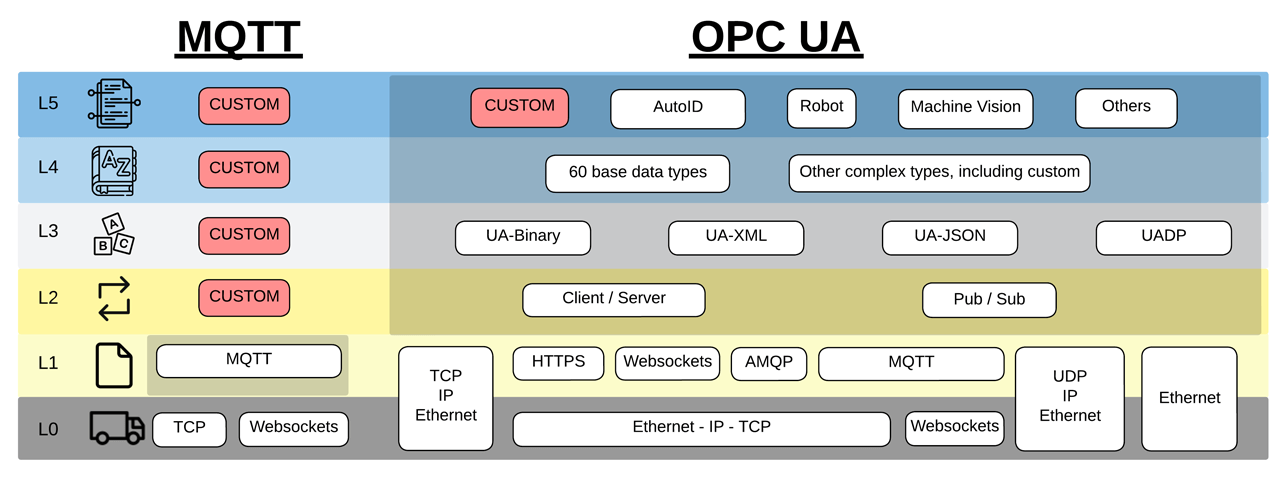
Regarding interoperability, the terms “OPC UA” and “MQTT” are undefined and originate from opposite sides of the same coin. As seen in the figure above, specifying MQTT for equipment only defines the base communication protocol, leaving all the remaining stack undefined, which levies a heavy burden for integrating consumer applications. Integration hurdles for the consumer include learning the topic paths implemented by the producer and determining whether an application can monitor the producer’s health through the Last Will Testament function. Also, a challenge is choosing which QoS level to use, whether producers are publishing on fixed time intervals or only on changed data, and many others. Even more daunting to integrators is that MQTT has no definition of the transmitted data, so the consumer application is forced to accommodate whatever the device selected regarding the encoding scheme, data types, and object definitions. Specifying “MQTT” is not enough if the goal is interoperability.
Whereas “MQTT” is undefined above the Communication Protocol layer in the Data Access Model, OPC UA has achieved standardization at every level of the Data Access Model. While definitions at each layer are an achievement matched by no other technology, the portfolio of specifications includes many choices at each level of the model. Given the plethora of communication protocols, encoding schemes, data types, and object definitions, simply connecting an OPC UA consumer to an OPC UA producer does not guarantee interoperability, as each application may select different options up the stack. An integrator must closely evaluate what options at each layer are implemented by the producer device and ensure it matches the capabilities of the consumer application. Or conversely, the integrator will know the consumer application capabilities and be forced to limit the scope of OPC UA products that he can utilize. Specifying “OPC UA” is not enough if the goal is interoperability.
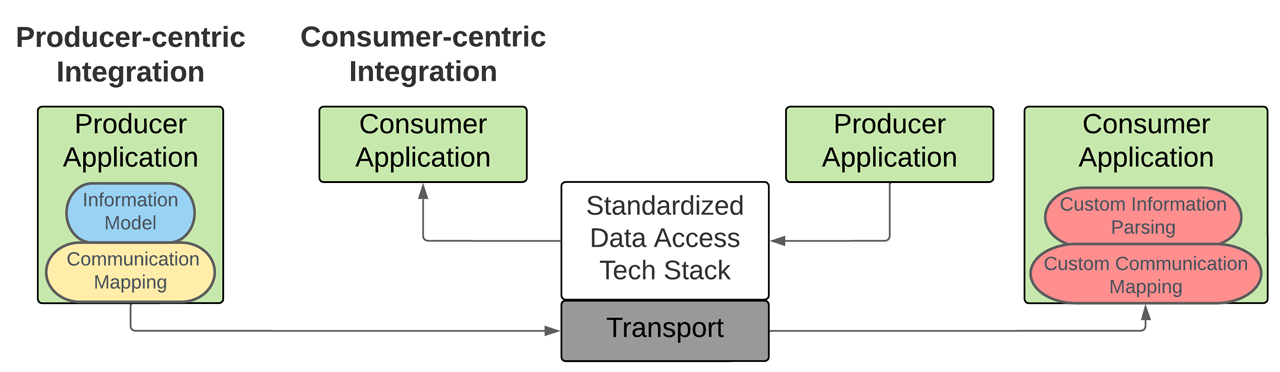
Consumer-centric Integration
Technology is only as good as the products that implement it. Unfortunately, when integrators and end users evaluate what Data Access technologies will be used within their enterprise, many prioritize the available technologies within devices and applications that produce data without considering the consumer applications’ capabilities. This producer-centric approach will lead to unforeseen costs or, worst-case, a failed IIoT deployment.
For example, before buying HD DVDs or Blu-ray Discs, one should first determine if the video player must be built or if the player can be purchased; the answer to this simple question determines which disc will be selected from the shelf. Therefore, a system architect should begin by considering the applications that receive data and exist in the market and then evaluate them based on their implemented technologies that minimize the cost of integrating devices at scale. After a Data Access technology demonstrates business value through consumer applications, an end-user will inevitably demand that future producer devices and applications comply with those selected technologies.
Consider a simple user story that has existed since the start of Industry 3.0: “As a data analyst of a multi-facility enterprise, I want an interface to access data originating from any facility so my single application can solve many different problems.” What is the industry standard for enabling this single application to connect to many data sources within the enterprise? Without a standard data access interface, system integrators will pursue the path of least resistance by continuing to provide end-users with custom communication and custom information definitions.
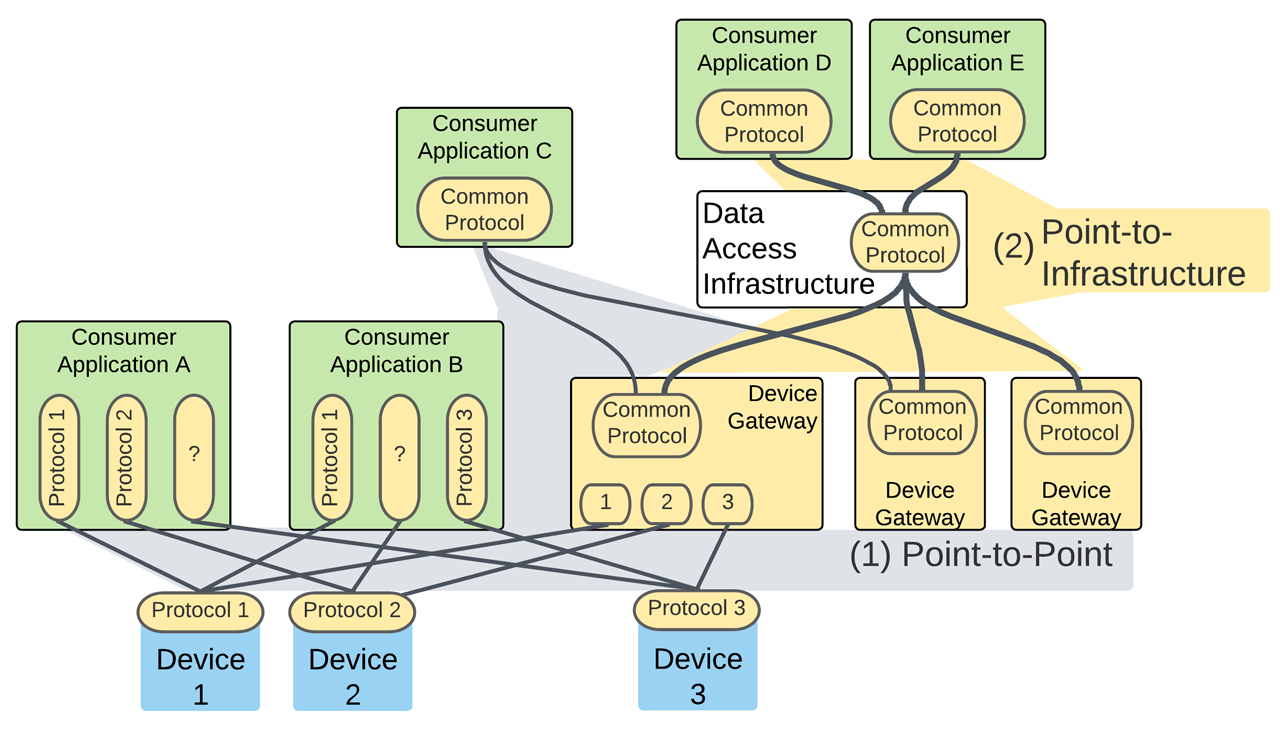
Industry 4.0: Decoupling Consumers from Producers
The most outstanding achievement of the TCP Model is connecting devices regardless of their location, all while allowing applications to maintain their existing connectivity strategies. However, over the past forty years, the unchanged connectivity strategy has been the problem facing most manufacturers embarking on their Industry 4.0 journey. The figure below highlights two common communication strategies: (1) “Point-to-Point,” which has been present since the beginning of Industry 3.0, and (2) “Point-to-Infrastructure,” which has gained popularity within Industry 4.0.
Within “Point-to-Point” architectures, the number of connections a consumer must initiate is directly correlated to the number of producers in the system. The number of producers also dictates the number of different protocols and custom parsing functions that must be engineered on the consumer’s side. As a result, the Point-to-Point model becomes unsustainable as the number of producers increases and the number of implemented protocols increases.
Enterprise systems have been challenged by the number of protocols required when collecting information from all plant-floor devices. The burden is too significant for applications to communicate with any protocol across all devices. There have been efforts to eliminate this burden by commonizing the plethora of protocols, but product adoption has been half-hearted. Rather than prioritize standardized protocols alone, automation OEMs continue to innovate atop native Fieldbus technologies such as EtherCAT, PROFINET, and EtherNet/IP. Nearly all devices continue to support Modbus/TCP for exchanging data, and some have added IO-Link. A few devices have progressed to include OPC UA Servers, but even high-volume OEMs that are members of the OPC Foundation still omit OPC UA Servers. Some integrators and end users await the latest device specification, OPC UA FX, expecting that it will result in greater market adoption. In contrast, others seriously doubt whether a standard protocol is even possible at the industrial device level.
While standards organizations continue convincing OEMs to standardize device connectivity technologies, a critical component of the Data Access architecture continues to be the Device Gateway. Whereas IT systems can be assumed to contain Ethernet interfaces, Operational Technology (OT) systems are not as homogenous. Many devices on the plant floor have physical interfaces that are not Ethernet, such as RS-232, RS-485, CAN, and others. Device Gateways protect a consumer application from the number of physical interfaces and device protocols while simultaneously providing consumer applications a single point of connectivity regardless of the number of devices. Additionally, it reduces the number of connections a device must service from all the consumers in the enterprise. As Device Gateways and consumer applications proliferate throughout the enterprise, however, Device Gateways then become the bottleneck for scalability within point-to-point connectivity.
Building Communication Infrastructure
In today’s market, the consumer application often resides within a cloud service provider, which favors scalable publish-subscribe protocols. If pub-sub is the most scalable strategy within cloud applications, how far down the manufacturing enterprise should those scalable technologies be leveraged? Conversely, the factory floor uses client-server protocols, which specialize in fast communication among static devices. If client-server is appropriate on the factory floor, how far up the manufacturing enterprise does client-server stop making sense? To minimize integration costs as the number of devices increases, an enterprise should expand to its lower levels the same technologies favored by cloud platforms. One of the most important architectural decisions is whether to use client-server or publish-subscribe when connecting to a cloud platform.
Consumer applications within cloud platforms commonly support publish-subscribe, allowing devices within an enterprise to initiate the connection to the cloud platform. End-user firewalls prefer this to a cloud application creating a connection through an open, inbound port. However, the challenge of opening inbound ports for OPC UA client-server architectures has been solved through the “Reverse Connect” function. This function allows a server/device to initiate a TCP connection to the client/consumer so the client can then have an open path through the firewall to begin the standard OPC UA application-level connection. Since “Reverse Connect” is a unique feature requiring reading producer devices’ fine print to determine its compatibility, system integrators will favor publish-subscribe architectures that inherently enable connectivity to cloud platforms.
In addition to connectivity benefits, publish-subscribe inherently allows consumer applications to discover the presence of new devices automatically. OPC UA client-server architectures solve the discoverability problem through Aggregation Servers that federate data from many OPC UA servers. Consumer applications connect to the Aggregation Server, and devices implementing “Reverse Connect” can initiate connections to the Aggregation Server through its well-known address. The consumer application, which is already subscribed to the Aggregation Server’s address space, can automatically access any newly added device.
Another OPC UA discovery architecture is to deploy a Global Discovery Server where devices register their presence to the server. The Aggregation Server can be a client and use that registration to initiate a connection to the device. The challenge for the OPC UA ecosystem is to define a microbrand of products, each of which implements OPC UA client-server functions of “Reverse Connect” or “Discovery Server” for all consumers and producers. Whereas OPC UA products can automatically discover devices within a network, lack of standardization ironically challenges integrators to locate these products within the commercial market. Integrators can readily find “MQTT” applications but finding available “OPC UA Aggregation Server including Reverse Connect or Discovery Server” compatible with “OPC UA client applications including Reverse Connect or Discovery Server” is undoubtedly more challenging.
Another capability of applications within cloud platforms is allowing multiple instances to be clustered together, either to increase system availability or to increase throughput through parallelism. Most enterprise-level MQTT brokers inherently include cluster functions to satisfy cloud-based applications’ availability or scalability needs. As a result, these application instances can be scaled on demand, allowing end users to optimize infrastructure costs using only the necessary computing resources. However, OPC UA client-server instances are more static and monolithic due to the focus on industrial and manufacturing applications. Therefore, supporting clustering functions would be considered the exception, not the rule.
Because MQTT is agnostic regarding the payload, it is used by many industries, from large IT companies to automotive companies and IoT platforms.
Exposing an MQTT broker to many use cases worldwide equates to identifying more issues and requesting more features, which translates to becoming a much more resilient product overall. OPC UA client-server aggregation applications are typically limited to industrial or manufacturing use cases which prolongs the timeline of achieving an equivalent level of application hardening.
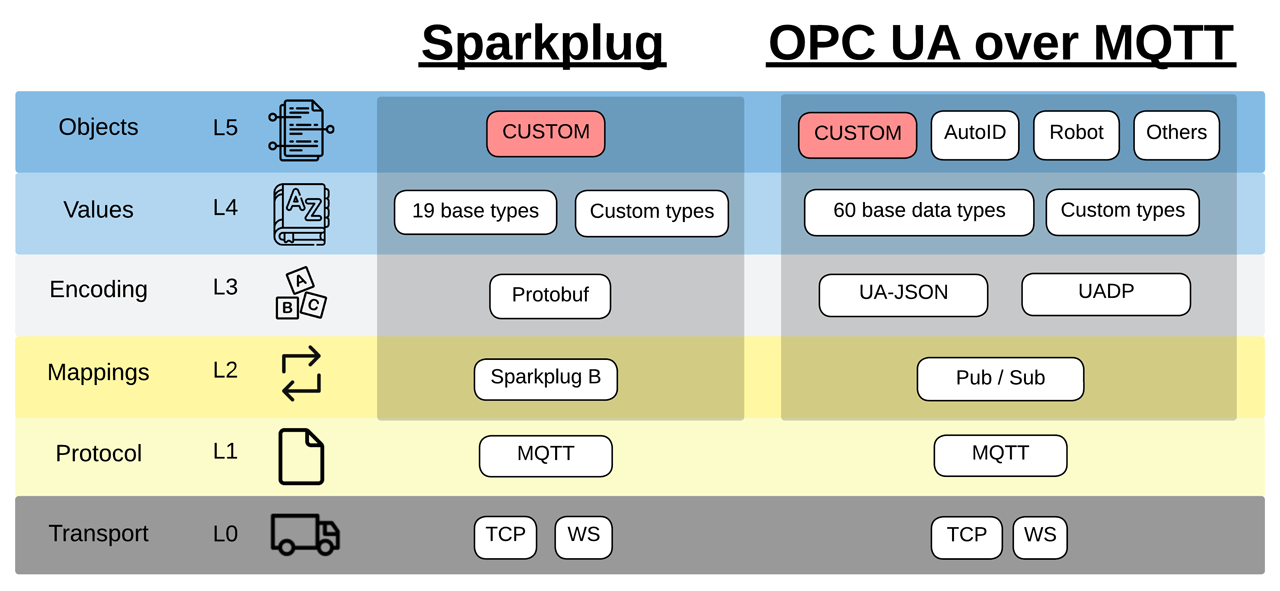
Combining Scalability with Interoperability
Many applications within the Internet of Things (IoT) space have leveraged MQTT as a lightweight method to publish data to any number of consumers. However, while MQTT enables scalability, it cannot facilitate interoperability on its own. The OPC Foundation, on the other hand, understands the integration challenges when only the Communication Layer is specified, and so they have standardized the entire stack from communication through information. Going further, the OPC Foundation advises that the Information Layer is of primary importance over the Communication Layer by saying, “it’s not about the protocol; it’s about the payload.” The Information Layer is shown to be OPC UA’s main value proposition, given that it dedicates over 4000 pages to specify information definitions, dwarfing its communication definitions at less than 300 pages.
Solving the lack of information interoperability over MQTT, the Sparkplug standard was created in 2015 to define explicitly (1) protocol mappings, (2) an encoding scheme, (3) common data types, and (4) a means for custom object structures. Sparkplug began as an unknown proprietary definition from Arcom/Eurotech to assist internal integrations over MQTT. Within a year, Cirrus Link used the technology to develop various third-party modules for Ignition, a popular SCADA/MES platform.
Ignition’s MQTT Engine module established a simple and obvious use case for Data Access interoperability. Sparkplug producers from any number of vendors publish information to a standard MQTT broker. The information, then, becomes immediately available and enumerated as tags and User Defined Types (UDT) within Ignition’s internal tag structure. However, the most impressive aspect of this function is that the discoverability of newly connected Sparkplug devices occurs automatically without input from an end user or integrator. In 2019, the Eclipse Foundation, an open-source organization, took ownership of the Sparkplug specification. Its popularity continues to increase due to Ignition allowing anyone to evaluate its platform through free and fully functional trial downloads, including a free Maker Edition that any hobbyist can use.
Whereas Sparkplug built its stack from the bottom up to define information over MQTT for interoperability, the OPC Foundation worked from the top down to specify publish-subscribe functionality for scalability. OPC UA Working Groups began developing standards to extend its existing information definitions through other use cases such as firewall traversal, controller-to-controller communication, controller-to-cloud communication, or connecting producers to consumers at scale through message brokers. Finally, in 2018, the OPC Foundation released Part 14: PubSub specification, where MQTT has become the most popular of its four communication protocols, primarily due to the market’s previous familiarity with MQTT from Raspberry Pi applications, home automation projects, or other IoT applications. Additionally, the UA-IIoT-StarterKit released in May 2021 features MQTT only, and recent OPC webinars primarily discuss “OPC UA over MQTT” when referring to PubSub architectures.
Challenges of Data Access Protocols
Figure 9Products able to consume Sparkplug information out-of-the-box, such as HighByte Intelligence Hub, Canary Historian, Cogent DataHub, OPC Router, and Sorba.ai can dynamically receive information directly from any number of Sparkplug producers. Then they immediately begin using that information by ingesting the producer’s data structures within their applications as native variables and object definitions.
Troubleshooting tools such as MQTT.fx and Wireshark include Sparkplug decoders so that the data can be reviewed across the wire. In addition to SCADA products like Ignition and FrameworX, cloud service providers such as Amazon Web Services, Azure, and Google Manufacturing Platform can receive Sparkplug data and translate it to their native cloud ecosystems through IoT Bridge for SiteWise, IoT Bridge for Azure, and the Manufacturing Connect Platform. These applications make it as simple to receive structured data: (1) specify the IP address of the MQTT Broker along with appropriate credentials, (2) determine what data group is of interest, and (3) use the application to consume the data.
However, the applications listed above are monolithic and designed for use cases that should receive all data from most or all producers. As a result, Sparkplug begins to show its limitations when deploying it across an enterprise and integrating applications that are smaller in scope. For example, applications that only want a single, slow-changing variable must wade through all data from a producer node, including fast-changing variables. Sparkplug requires that producer nodes combine data variables into monolithic structures, which wastes bandwidth and computational power for applications with more minor use cases. Additionally, a consumer application must have a command path through MQTT brokers to the producer node to request the latest state of variables and metadata to be published. This architecture is a non-starter for enterprises that require data to be delivered only one way, away from the production process. Finally, Sparkplug uses only one encoding scheme, simplifying consumer application development. Still, it can be too challenging to require existing applications to add support for the Protobuf binary encoding.
As the discourse around Data Access has more recently focused on publish-subscribe technologies, a new term is gaining popularity: “OPC UA over MQTT.” While it is formed from two undefined terms, as previously discussed, the goal of this new term is to define an OPC UA technology stack that enables both interoperability and scalability. Reducing The extensive portfolio to just a single communication protocol still presents interoperability challenges due to the many options at each layer of the Data Access model.
For example, “OPC UA over MQTT” includes ingesting UADP binary encodings, which can reduce bandwidth costs of data transmission, or ingesting JSON, which can feed existing cloud data pipelines. OPC UA applications include native metadata handling, such as engineering units received through published NodeSet fragments. Additionally, OPC UA applications include automatic retrievals of unknown OPC UA object definitions through a UA Cloud Library. This function allows users to easily store custom object definitions alongside standard companion specification definitions, such as AutoID, Machine Tool, Robots, or Machine Vision. Consumer applications cannot be expected to support all these functions, so even targeting “OPC UA over MQTT” is not enough to avoid manual integrations.
The OPC Foundation announced in February 2022 that six cloud service providers “either support OPC UA over MQTT in their products today or that it is on their development roadmap.” This announcement was significant because it signaled that Amazon Web Services (AWS), Google Cloud, IBM, Microsoft, SAP, and SIEMENS would be compatible with the OPC UA portfolio atop the MQTT protocol. Even more impressive is that this announcement signals the possibility of multi-cloud architectures within enterprises, allowing users to move data seamlessly from one cloud vendor to another, achieving cloud-to-cloud interoperability. Revealing the prevalence of OPC UA over MQTT, the OPC Foundation stated in April 2022 at OPC Day International that there are thousands of implementations.
For end users and integrators needing to identify consumer applications of OPC UA PubSub technologies, the OPC Marketplace was created in June 2022 as a webpage accessible to the public allowing filters based on Function, Transport, Application Profile, and many other criteria. Whereas ubiquitous market support has been assured, no timeline has been announced for any OPC UA over MQTT products to be listed on the OPC Marketplace, including products from the six cloud service providers. Being informed of what is available on the market remains a challenge for end users and integrators who require commercial-off-the-shelf consumer products to build comprehensive Data Access architectures.
Starting over: Industrial Interoperability Begins with the Consumer
Recall the simple user story that has existed since the start of Industry 3.0: “As a data analyst of a multi-facility enterprise, I want an interface to access data originating from any facility so my single application can solve many different problems.” However, what universal data interface has been developed for manufacturers? What standard exists where multiple products can be purchased, each of which has been tested against a minimum set of functions to ensure that the data analyst’s application will work as intended?
Now consider the experience of most home users who live within a world of technological interoperability, often without even realizing it. Connect a PC to the internet leveraging DNS (defined in 1983) and DHCP (defined in 1993). Plug in a USB Mouse (defined in 1996) from any vendor and watch it work with a PC from any manufacturer on any number of Operating Systems. Select any number of browsers to access the same content from web pages (defined in 1995). Interoperability is not a new problem, and it was solved by these specifications and successfully transferred to the market over 25 years ago.
Industrial technologies have been developed, and many OEMs have used these technologies to produce products that fill the interoperability void. For example, Sparkplug is a narrow and focused standard that drives interoperability but only for a particular type of consumer application. On the other hand, OPC UA is as flexible as a bag of standard Legos poured onto the floor but purposely omitting the assembly instructions, so customized functions and interfaces between OEMs products are inevitable. Additionally, after limiting the portfolio to “OPC UA over MQTT,” producers are allowed to embed any topic path, thus requiring consumer applications to accommodate their selections, much like the custom integration challenges found within the MQTT-only tech stack. Interoperability for Data Access within the industrial market, however, must enable an application to be developed and be equally compatible with products produced by any OEM.
Unfortunately, efforts over the past 25 years have yet to produce a universal interface to enable the simple use case of data access interoperability. If data access has not been solved, what confidence should the industry have in the existing efforts to achieve interoperability for other functions such as Events, Command and Control, Historical Access, and many others? What excuse does the manufacturing industry have for not accomplishing the same success demonstrated by everyday IT products, even when having access to the same technologies?
The industrial standards committees must shift from defining producers that levy integration burdens on consumers to focusing on the most straightforward use cases and defining technologies to solve those problems with the least amount of development effort from the consumer. For example, configure a consumer application with the IP address of a Remote IO rack along, specify an IO point’s slot or terminal location, and then immediately get data in a meaningful way, including engineering units. Then install a replacement Remote IO rack from another vendor, and watch the original application work by specifying a new IO point location if necessary. The problem facing manufacturing, however, is much larger than enabling simple point-to-point connectivity use cases, which should have been solved over 25 years ago.
At the enterprise level, even the most basic function lacks a standard definition: how should an application be developed to access information so it will work as intended when connected to products from any OEM? To use an analogy, all the work of data access standardization thus far has claimed victory after defining the low-level electrical and plumbing codes before even determining how its building should look. It is time to stop focusing on the plumbing and, instead, become laser-focused on what kind of buildings should exist.
Enterprises adopting Industry 4.0 paradigms prioritize consumer applications during architectural development. Producer devices within the plant floor are largely static once commissioned. In brownfield deployments, device gateways can be deployed to bring legacy systems into compliance with the needs of the consumer application. As companies mature on their digital transformation journey, new information will appear, and applications will be deployed to consume it. The cost of integrating consumers into the enterprise must be minimized so small-value problems can be solved alongside large-value projects. An architecture that depends upon manual integrations for propagating information throughout the enterprise will limit the speed of innovation within the manufacturing and business processes. Architectures targeting technologies that enable easy integration of consumers will be prepared for the inevitable tsunami of applications looking to provide value for its business.
Standardizing Communication Infrastructure
Just as the TCP Model uses Ethernet switches to overcome the hurdle of connecting devices in different physical locations, a communications infrastructure implementing Data Brokers overcomes the burden of connecting consumers to data distributed across machines. Simple enterprise deployments can include a single, central Data Broker, whereas more complicated deployments can appear like network reference architecture diagrams detailing Core, Distribution, and Access switches.
As shown in the figure, “Point-to-Infrastructure” architectures enable a consumer application to use a single Data Broker IP address rather than being required to know about the IP addresses of the individual devices producing data. Additionally, the application only needs to implement a single communication protocol, dramatically reducing the burden of application development and commissioning efforts. The consumer application informs the Data Broker what data is of interest, and any data matching those criteria is immediately available. These benefits persist regardless of the number of producers placed on the network, which is why this architecture is scalable.
Once data is available at the enterprise level, applications can then begin consuming the data in any number of ways. For example, a business may be interested in the power levels across all equipment within the enterprise to evaluate the difference in energy consumption during an active shift compared to an idle shift.
The equipment generating this data resides on the plant floor, and the primary way to organize its information is by its location within a hierarchy of Plant / Area / Line / Cell. Most deployments will couple this location hierarchy to the data structure within a Data Broker. However, this data structure is a producer-centric approach that ignores consumers interested in specific data regardless of location. Any criteria driving a static data hierarchy within a Data Broker is not a consumer-centric approach as it does not facilitate requesting data irrespective of the attribute of interest.
Whereas a Data Broker decouples the connectivity of consumers from producers, the consumer remains strongly coupled to the number of producers. Data Brokers are just like Ethernet switches and do not define (1) how the data is encoded, (2) what datatypes are possible, and (3) what the data represents.
Each producer, therefore, may have its custom information definition, which will require an equal number of custom integrations within each consumer. Another layer of standardization is necessary above the communication infrastructure to further simplify data access for the consumer.
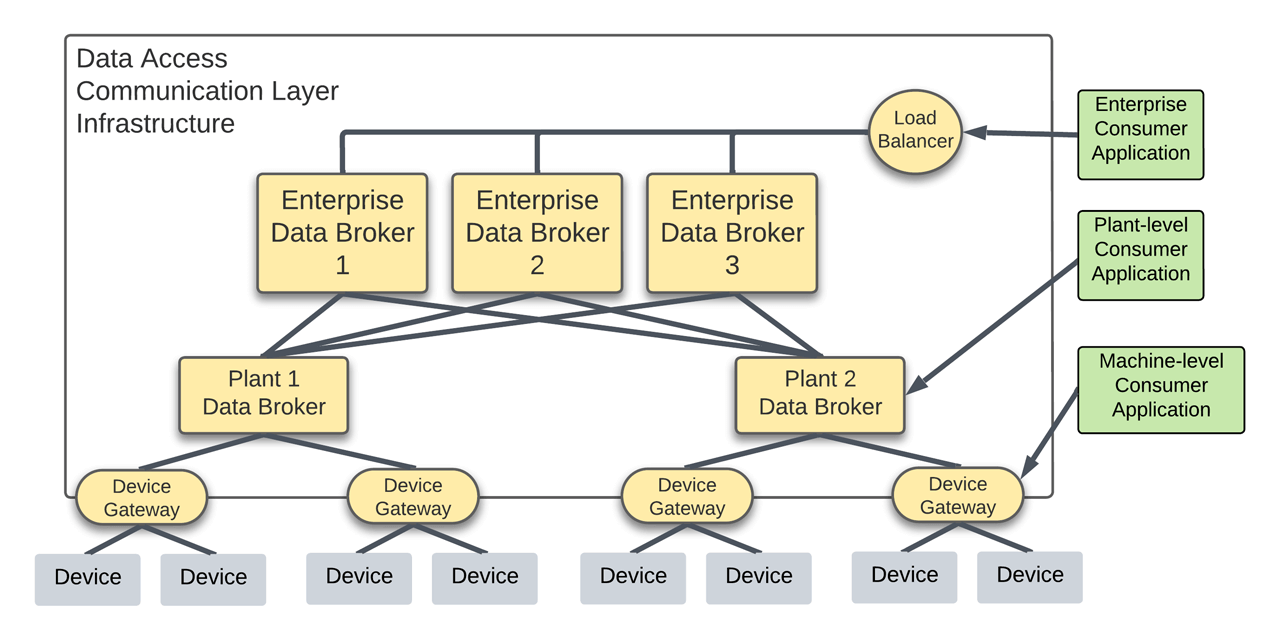
Standardizing Information Infrastructure
Just as Device Gateways translate all the various industrial communications protocols, an Information Gateway commonizes all the different information encodings and structures. This central application enables information to be requested in meaningful ways, including dynamic filtering based on various attributes. No matter the number of information schemes or structures implemented by producers, consumer applications only need to be aware of a single information definition to receive that data through the Information Gateway.
Through a lightweight and standardized information interface, it enables both request-response patterns as well as subscription patterns. For example, an application can request a list of data to browse for what is available. This response includes data and descriptive metadata, which is static information tightly related to the underlying dynamic data. For example, metadata can include properties and attributes of data such as engineering units, calibration dates, location information, and many others. The metadata typically allows applications to filter for the data of interest when creating subscriptions. The gateway is consumer-centric by providing data through a handful of encodings. The client can inform the gateway which one it prefers based on different use cases, such as JSON or binary formats.
In addition to translating the various ways of representing the data, the Information Gateway shields applications from needing to know the inner workings of the underlying Data Brokers, such as the topic hierarchy. For example, DNS helps web browsers from needing the IP address of a webpage. Similarly, an Information Gateway translates an object name that is beneficial for humans into a cryptic topic name optimized for applications.
Within today’s systems, integrating data producers requires knowing ahead of time what static publish path should be used for the data. Very often, this publish path is optimized for human readability rather than optimized for network bandwidth capabilities or data consumption patterns. The constraints of today’s static topic names can be solved, however, with the Information Gateway behaving like a Dynamic Host Configuration Protocol (DHCP) server.
For example, when integrating a new data producer into the communication infrastructure, rather than using a static Data Broker IP address and static publish path, the producer may be configured with the address of the Information Gateway. The producer automatically connects to the Information Gateway, requests how its data should be published, receives a Data Broker address with a publish path, and then connects to the Data Broker to begin publishing the data. The broker and publish path provided by the Information Gateway can be based dynamically on any number of attributes as determined by enterprise architects, such as the device’s physical location, type of device, or amount of data.
This dynamic request/response behavior for determining publish paths enables architects to centrally control how the data is published within the enterprise. It also enables network bandwidth optimization efforts not currently possible through statically defined publish paths. Deploying an automated information system may result in data traversing across many brokers as a swarm of unintelligible topic paths. However, fear not; this is already familiar territory for network architects capturing ordinary TCP/IP traffic from existing network switches.
After implementing a Data Broker and an Information Gateway, consumer applications become entirely decoupled from producers at the Transport and Communication Layers. This architecture allows consumers and producers to scale out significantly without much integration effort. The effort can be reduced further by deploying devices natively supporting the enterprise-wide Communication protocol and Information definitions. Once this is achieved, zero-effort integrations are possible; consumers immediately receive information as soon as producers are connected to the Data Access infrastructure.
Wading through the Transition
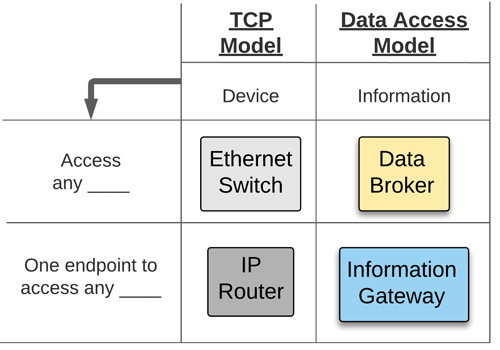
Some within the industry suggest that data access architectures should first standardize on a communication method. Others recommend that the focus should be on standardizing the information. Unfortunately, as has been discussed, the terms “MQTT” or “OPC UA” do not move manufacturers any closer to the goal of interoperability. Interoperability for Data Access goes beyond the particulars of the protocols at the Communication Layer and data definitions at the Information Layer. When looking to achieve Data Access interoperability, the focus must start with the Information Gateway, the single interface for a consumer application.
While there are various technologies defined and multiple products on the market that can serve information, the specific interface and function of the Information Gateway need to be standardized. The industrial market, therefore, is wide open for OEMs to develop products with custom interfaces and for end users to receive custom definitions of an Information Gateway and how it functions. Additionally, the lines between Information Gateway and Data Broker are beginning to overlap with newer products on the market. For example, Communication Layer software is starting to incorporate functions to allow some amount of Data Ops within their product. Additionally, Information Layer software primarily focused on Data Ops is beginning to include communication components such as MQTT Brokers.
As long as this critical definition remains undefined, data access interoperability will continue to be an elusive goal for the manufacturing industry. During this transitional period, end users and integrators must do their best with what is available. Since there is no standard defining the Information Gateway or the Data Broker, it is critical to begin with the consumer and then determine the interface for the producer. The Data Access Infrastructure must inherently eliminate the cost of integration when adding consumer or producer applications. Achieving a scalable architecture readies an organization to accommodate the multitude of use cases revealed as more data becomes available.
The first step in developing an architecture is to identify the primary consumer applications and define their requirements for information. Given that technology is only as good as the products that implement it, selecting an Information Gateway will inevitably include a make-versus-buy analysis, which determines if the solution will be a commercial-off-the-shelf platform or a full-custom solution. To assist the study, end users, integrators, and OEMs should consider using NASA’s Technology Readiness Level (TRL) metric.

The TRL metric is scaled (1-9) to evaluate the maturity of a technology according to completed demonstrations. As the value of the metric increases, more of the system has been functionally demonstrated within environments of increasing fidelity: from artificial to relevant and then to operational. The figure on the bottom of page 51 adapts NASA’s entrance criteria for manufacturers to guide discussions and evaluate risk among emerging data access technologies. It allows end-users, integrators, and OEMs to objectively decide what level of technical risk they can tolerate within their products and systems and communicate that to external parties.
When defining the scope of the Information Gateway, the interface and function must stay computationally lightweight, narrow in scope, and easy for consumers from multiple OEMs to implement. This interface will enable consumers to connect to a single endpoint to access information produced in any format within the enterprise. This standard interface, however, should be extensible to include other critical use cases such as events, historical access, and alarms.
Additionally, parts of the infrastructure must be identified to own the Data Ops process to transform various information definitions into the standard definition required by the Information Gateway. Smaller deployments may benefit from embedding the Data Ops function within the Information Gateway. Larger deployments, however, may distribute the Data Ops function across the enterprise and allow the infrastructure to scale as the number of producers and consumers increases.
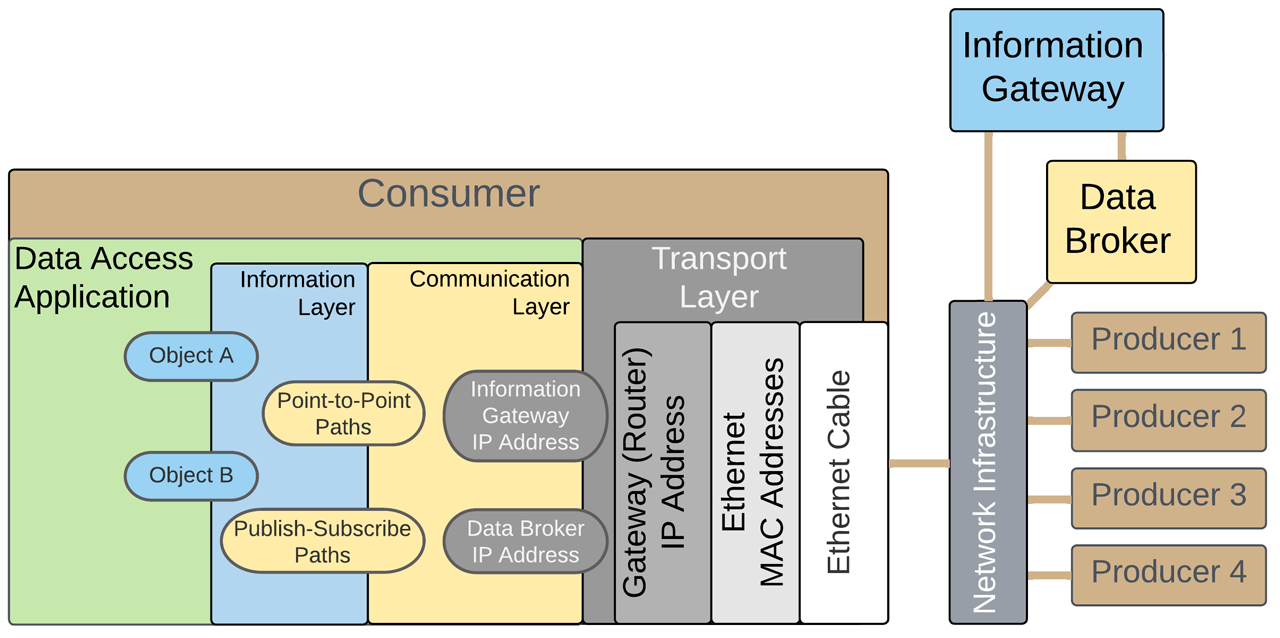
After selecting an Information Gateway and establishing the Data Ops infrastructure, communication protocols should be chosen to move data from the producers to the Information Gateway within the confines of the planned network infrastructure.
A deployed Information and Communications architecture will then levy interface requirements upon the producers, where conforming to these definitions enables integration at scale. However, where instantiating this interface definition within the device is impossible, account for efforts to manually integrate the custom information definitions through additional Data Ops or communication definitions through Device Gateways.
The industry desperately needs a standard definition of the interface and function of an Information Gateway and a Data Broker. Unfortunately, the current state of the market is reminiscent of the days of the protocol wars from forty years ago, before Ethernet switches and routers could be purchased from any number of vendors and form a functional infrastructure with minimal integration.
Until a simple stack is defined for the market to coalesce around, OEMs will continue to produce custom solutions, and end users will continue to expend their energy comparing the benefits of the technologies of each. Rather than settling for custom communication and information definitions or focusing on information models for specific industrial domains, let us focus on defining a standard Data Broker and Information Gateway that will transcend any single industrial environment. A transformed industry lies ahead, waiting only for a few decisive Data Access Architects to focus on making the integration of data consumer applications painless.