

TechnologyJuly 17, 2024
Operational solutions for industrial network resiliency

Industrial networks are characterized by their need for timely data transmission and high reliability. The occurrence of a single point of failure within the network can disrupt communication between machines, imposing operational challenges to industrial automation systems.
In the industrial world, fast recovery and fault-tolerant networks are critical for ensuring process operations and reliability. In this article, we will explore the significance of network resiliency protocols in mitigating downtime and safeguarding critical processes, which are vital in environments where system failures equate to substantial risks and costs.
In industrial environments, such as energy production, railway systems, maritime operations, and manufacturing, ring topologies are commonly deployed to interconnect machinery, sensors, meters, and control systems across extensive geographical areas, plant-wide manufacturing cells, where network connectivity may be constrained.

These industrial networks are characterized by their need for timely data transmission and high reliability. The occurrence of a single point of failure within the network can disrupt communication between machines, imposing operational challenges to industrial automation systems. Consequently, conventional spanning tree protocol is inadequate, as it does not offer sufficiently rapid convergence in the event of network disruptions within these specific settings.
Ring topologies and redundancy protocols
To address these challenges, advanced layer 2 protocols have been developed to effectively manage network rings. These protocols ensure fast convergence times on the order of sub seconds, manage redundant network paths, and prevent loops. Protocols such as the Cisco Resilient Ethernet Protocol (REP), Device Level Ring (DLR), Media Redundancy Protocol (MRP), High-availability Seamless Redundancy (HSR), and Parallel Redundancy Protocol (PRP) are widely implemented in such scenarios.
Resilient Ethernet Protocol (REP)
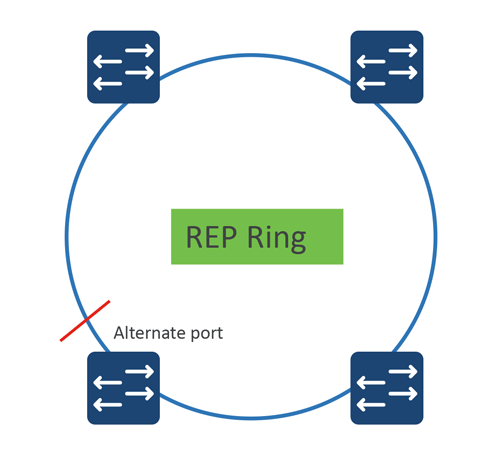
REP ring topology.
The Resilient Ethernet Protocol (REP), a proprietary protocol developed by Cisco for use in ring topology, can recover from link or node failure in 50ms. It operates by chaining ports within a logical grouping known as a segment. When all ports are operational, the protocol designates one port to be blocked. This port is called an alternate port. Data is not forwarded through a blocked port, but the local link status between adjacent neighbors continues to be monitored for topology changes.
In the event of network failure, the protocol unblocks the blocked port, which then transitions to forwarding state, thereby resuming traffic flow.
Resilient Ethernet Protocol is feature rich. It also facilitates VLAN load balancing which optimizes the distribution of network traffic. It supports complex ring topologies such as multiple rings and subrings and is interoperable with spanning tree protocol.
While REP ports do not run simultaneously with the Spanning Tree Protocol, it is possible for a switch to support both a REP ring and STP concurrently. In such configurations, if the REP segment detects a failure, it sends out an STP Topology Change Notification from the REP ring to accelerate the STP’s convergence process.
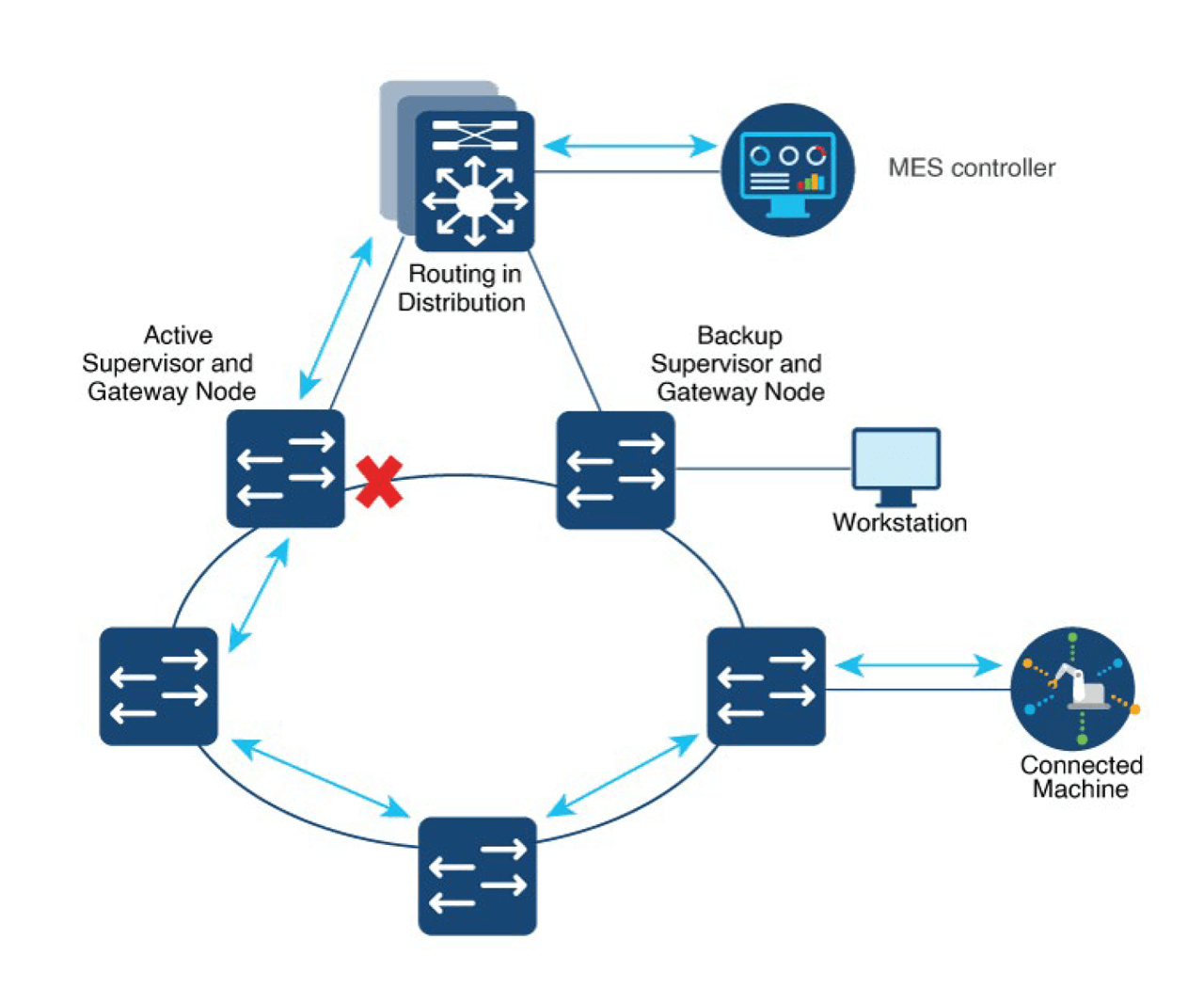
DLR ring topology with gateway node bridging between DLR and external network.
Device Level Ring (DLR)
Device Level Ring (DLR) is an EtherNet/IP™ protocol defined by the Open DeviceNet® Vendors’ Association (ODVA), generally found in manufacturing. DLR is designed primarily for a simple, single-ring topology that requires fast convergence. It does not support overlapping rings.
In DLR network, at least one device is configured as the ring supervisor. Ring supervisor monitors the health of the ring by sending beacon frames to detect network integrity. Each device along the ring relays the beacon frames to the next hop. If beacon frames fail to reach the secondary port of the supervisor, or a links status message is received from ring nodes, the supervisor unblocks the blocked port to resume traffic flow.
DLR does not interoperate with other redundancy protocols such as spanning tree protocol. A gateway node in the ring serves as a bridge between DLR ring and external networks, transmits frames to ports that are not part of the DLR network.
The default beacon interval is 400 microseconds, which enables ring recovery times of approximately 3 milliseconds for a ring consisting of 50 nodes.
Media Redundancy Protocol (MRP)
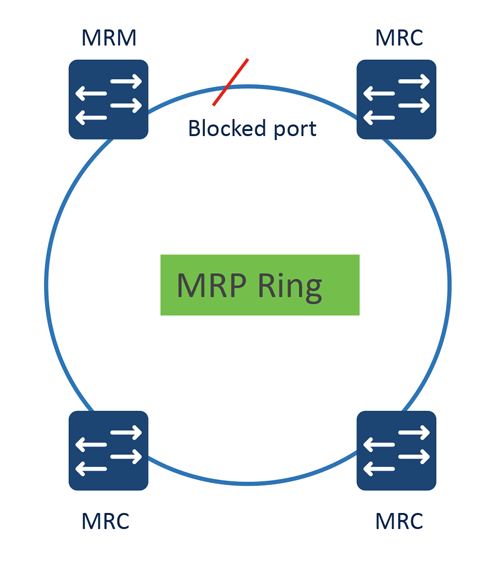
MRP ring topology
Media Redundancy Protocol (MRP) is defined in the International Electrotechnical Commission (IEC) standard 62439-2, commonly deployed in conjunction with PROFINET in manufacturing.
In an MRP ring topology, there are typically two roles of devices – Media Redundancy Manager (MRM) and Media Redundancy Clients (MRCs). Media Redundancy Manager manages and monitors the health of the ring, while the Media Redundancy Clients are the member nodes of the ring.
Media Redundancy Manager regularly initiates and circulates control frames from one of its ring ports and receives them back from the ring over its other ring port, maintaining bidirectional checks to monitor the health of the ring. To avoid network loop, Media Redundancy Manager keeps one of its ports in blocked state during normal operations.
When detected failure or recovery, Media Redundancy Manager sends out TopoChange frames via both of its ring ports to Media Redundancy Clients to quickly react to the network change.
If Media Redundancy Clients detects a port going offline or coming back online, it relays this information to Media Redundancy Manager by sending LinkChange subtype frames.
Media Redundancy Protocol supports multiple MRP rings and is interoperable with spanning tree protocol at uplinks.
Lossless resiliency protocols
While network protocols like Spanning Tree Protocol, Resilient Ethernet Protocol (REP), Media Redundancy Protocol (MRP) and Device Level Ring (DLR) detect network faults and reconfigure network path in the event of network failures, network recovery times can vary from seconds to milliseconds.
Lossless resiliency protocols such as High-availability Seamless Redundancy (HSR) and Parallel Redundancy Protocol (PRP), on the other hand, are designed to deliver uninterrupted redundancy, well suited for critical Industrial Automation and Control Systems (IACS) infrastructure that requires zero recovery time to maintain continuous operation and maximum up-time in the event of network disruptions.
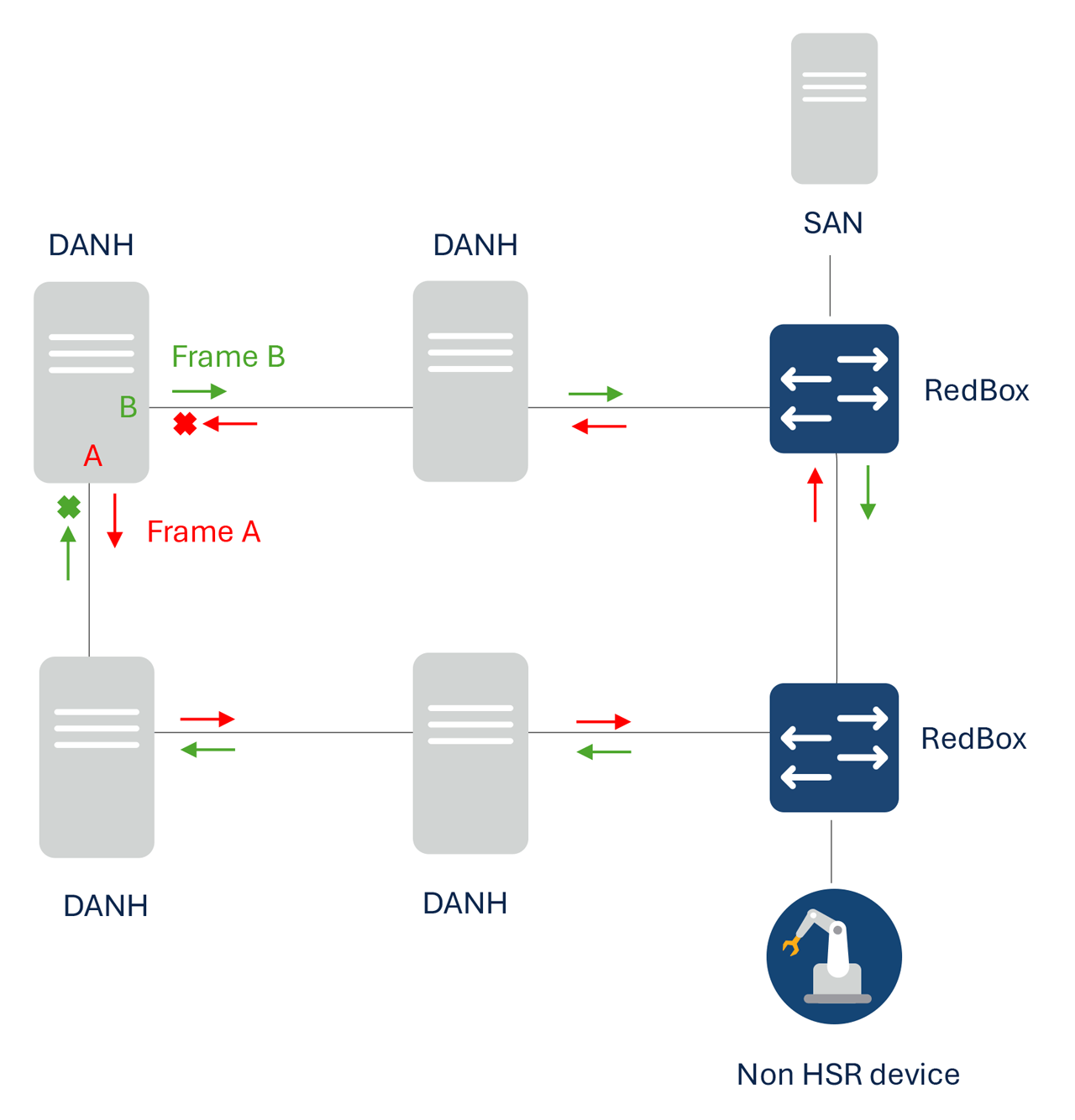
HSR topology with duplicated packets sent to clockwise and counterclockwise directions.
High-availability Seamless Redundancy (HSR)
High-availability Seamless Redundancy (HSR) protocol, as defined in International Standard IEC 62439-3, is designed for ring topologies to attain zero recovery time, ensures no frame is lost in the event of a network failure. HSR operates by sending duplicate packets over a ring topology.
In HSR network, HSR end nodes participate in implementing redundancy. They are implemented in a ring with two interfaces per end node, and relaying frames between these two interfaces called port A and port B.
Nodes with dual interfaces connected to the HSR ring are known as Doubly Attached Nodes implementing HSR(DANH). Singly Attached Nodes (SAN) are connected to the HSR ring through a RedBox (Redundancy Box), which serves the role as DANHs to provide connectivity and redundancy on behalf of the SAN. Devices that do not support HSR are connected to a Redbox, from which the Redbox generates the HSR headers on behalf of these devices.
HSR end nodes send a duplicated copy of packets to destination to both the clockwise and counterclockwise directions in the ring, with the addition of HSR header which contain a sequence number for the end node to decide which frames to be used or discarded. When the designated node receives the first frame, it removes the header and processes the frame. When the duplicated packet arrives, the node discards the frame with the same source address and sequence number.
If failure occurs in the ring, there is always another copy flowing through the network. Therefore, the HSR system can provide zero switchover time, lossless redundancy during failure and recovery.
In contrast to common ring redundancy protocols that only one primary path is active at a time which result in frames drop during convergence, HSR maintains continuous traffic flow over the other ring direction uninterrupted, and hence zero recovery time could be achieved.
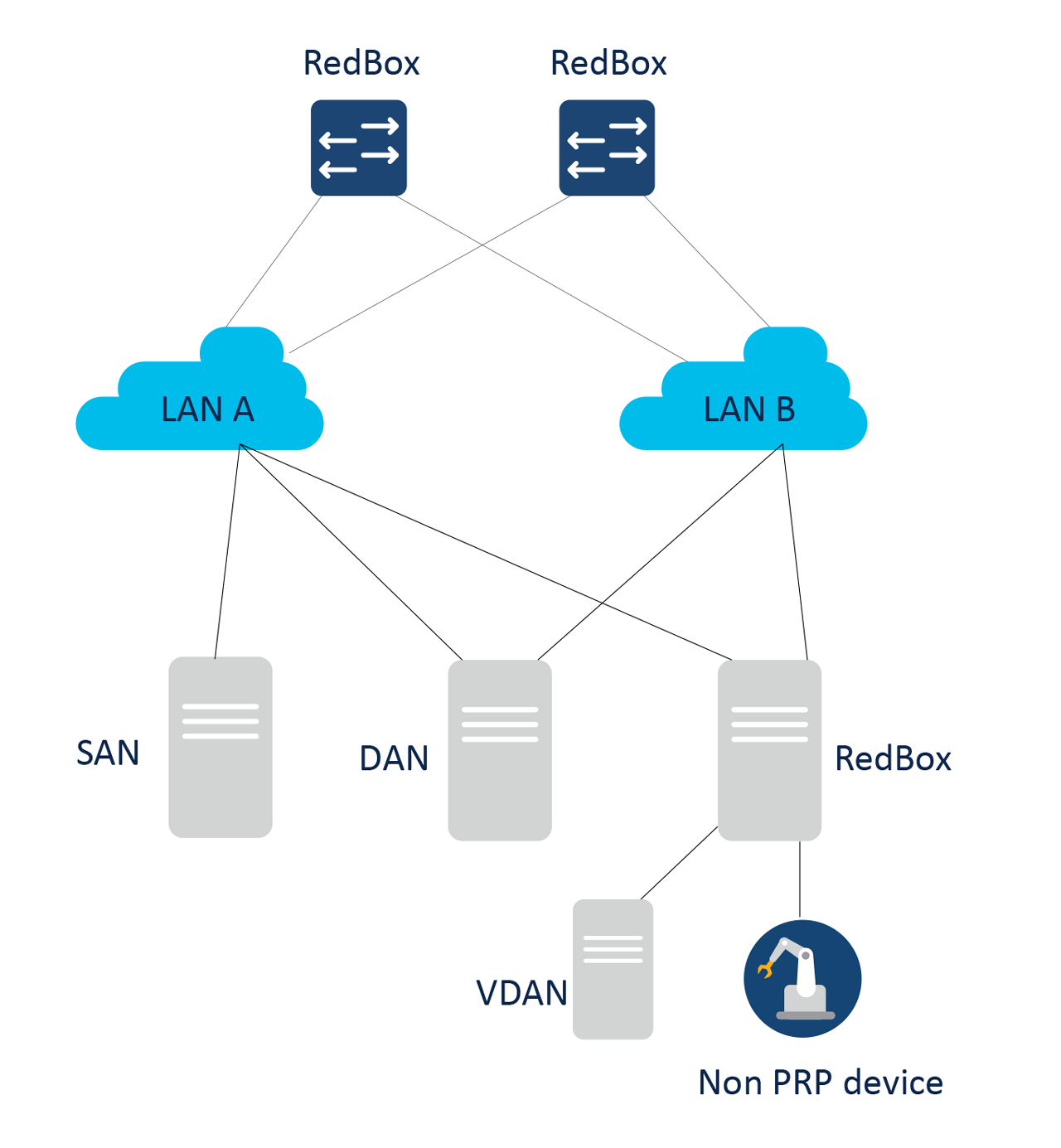
PRP topology with two parallels and disjoint LAN-A and LAN-B network.
Parallel Redundancy Protocol (PRP)
Parallel Redundancy Protocol (PRP) is another hitless redundancy protocol, designed to interwork with arbitrary network topologies and is not limited to ring implementations. It operates by sending duplicate packets over two independent, disjointed, layer 2 parallel networks referred to as LAN-A and LAN-B, thereby offering a flexible option that can be seamlessly integrated into existing network topologies, and there is no requirement for LAN-A & LAN B switches to be PRP aware.
In PRP network, PRP end nodes also participate in implementing redundancy. When a Dually Attached Nodes (DANs) transmits data, it sends two identical packets simultaneously across LAN-A and LAN-B to the destination. To differentiate between these duplicates, a redundancy control trailer (RCT) containing a sequence number is appended to each frame. When the designated node receives the first frame, it processes the frame and discards subsequent duplicate frame. In the event of a path failure, the unaffected path ensures continuous data flow, negating the need for recovery period.
Endpoints that connect solely to one of the networks, LAN-A or LAN-B, are known as Singly Attached Nodes (SANs).
In scenarios where an end node is not equipped with dual network connections, or does not implement PRP, it is typically connected to a RedBox which facilitates both connectivity and redundancy. A node connected behind a RedBox appears to other nodes as if it were a DAN and is therefore called a Virtual DAN (VDAN). The RedBox itself functions as a DAN and acts as a proxy for its VDANs.
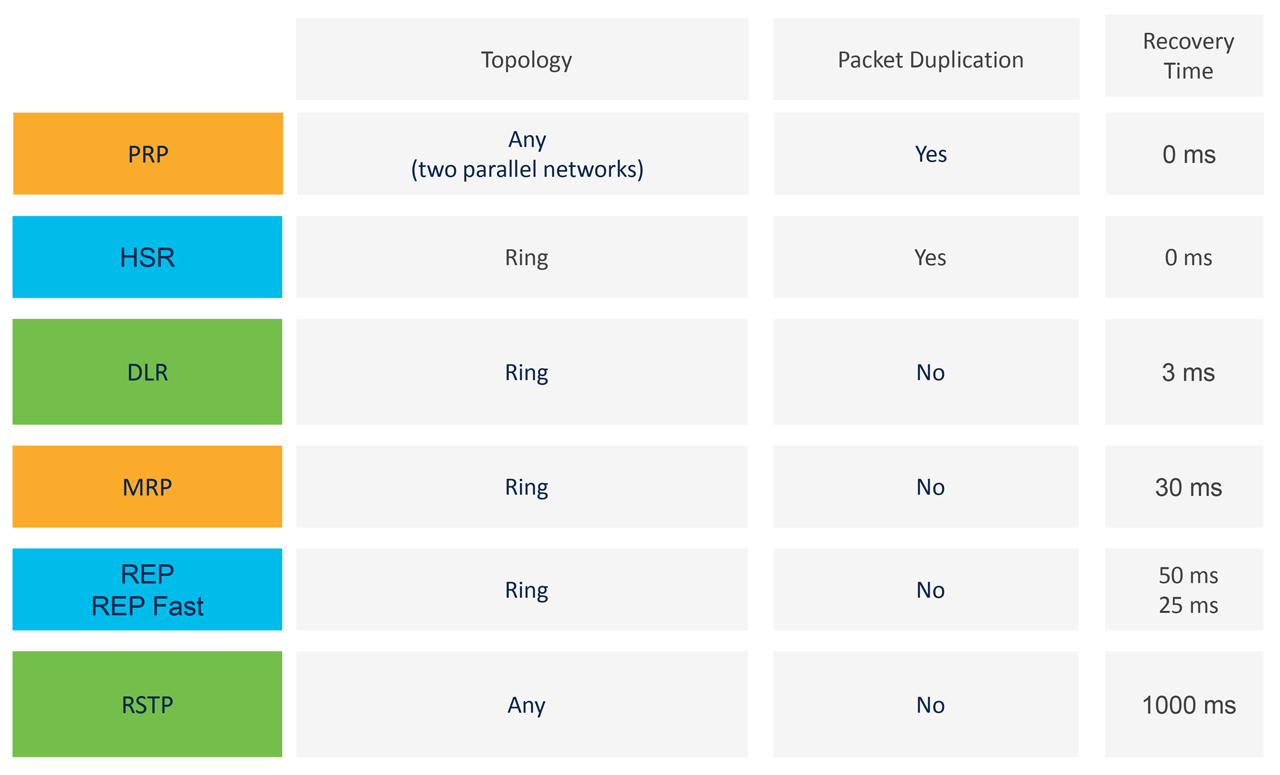
Redundancy protocol comparison.
Redundancy Protocol Considerations
The choice of redundancy protocols depends on the specific requirements of the network, the criticality of avoiding frame loss, and other key factors.
- Application requirement of convergence time: The specific requirements of industrial systems or applications influence the choice of protocol. HSR and PRP support zero convergence time, REP and MRP offer convergence times at around 50 ms for fiber connection and 3 ms respectively, and DLR typically offers fast recovery times suitable for EtherNet/IP networks.
- Network topology: Network topology plays a role in protocol selection. HSR is designed for ring topologies; PRP can be deployed in any topology if LAN-A and LAN-B are two disjoint networks; DLR is specific to EtherNet/IP rings, REP is used for general ring topologies with benefits such as VLAN load balancing, and MRP is typically found in PROFINET networks.
- Industry standard: It is crucial to ensure the choice of protocols adhere to industry standards and certifications if it is a mandatory requirement. HSR and PRP are based on the IEC 62439-3 standard, while MRP is based on the IEC 62439-2.
- Ease of configuration and troubleshooting: Ring protocols are generally easy to set up and troubleshoot. While HSR and PRP offer highest availability, they also come with increased complexity and specific requirements. For instance, end hosts must support HSR or PRP. Additional network bandwidth is required for duplicated packets, and PRP requires two separate and parallel networks for LAN-A and LAN-B.
Minimize downtime, maximize efficiency
Cisco industrial networking solutions are designed to be robust and resilient. Cisco Industrial Ethernet switches enable users to build highly resilient deterministic networks that help you minimize downtime, enhance reliability, increase process efficiency, and reduce operating costs. With support for several different redundancy options, Cisco switches also provide the flexibility to choose the redundancy mechanism that works best for individual use cases. Please visit cisco.com/go/ie, or setup a free, no obligation, call with one of our industrial networking experts.
Casca WM Kwok, Technical Marketing Engineer – Industrial IoT, Cisco