

TechnologyMay 30, 2021
TSN Technology: Ethernet Frame Preemption, Part 1

Ethernet Frame Preemption is a new extension to Ethernet. Part of TSN, it guarantees a constant cycle time for (industrial) applications. Why this extension is necessary, and the way it works is described in the first of this two part article.
In order to fulfil the needs of a control application, i.e. for a machine, robot, CNC-machine, or any other application requiring real-time processing, all components of such a system must work in a predictable manner. This also holds for any network used: messages must be delivered in time (or at least: not too late). But when Ethernet is used, there is no guarantee that this will happen. Traditionally, the “solution” is to keep the load on the network as low as possible; some vendors recommend to not go higher than 3%.
The problem with Ethernet is that it allows any device to send messages at any moment. Sometimes this is just too much for the network to handle. Messages are then queued in a “FIFO” manner: first-in, first-out. A message with high urgency can then be delayed by messages in front it, which just happened to arrive a little bit earlier. You recognize this probably: the same happens on the highway during rush-hours.


Figure 1: Ethernet and the highway have the same usage model, which sometimes leads to unpredictable delays.
In some industrial Ethernet protocols, like EtherCAT and Profinet, solutions have been invented to guarantee predictable behavior. But these are always protocol-specific solutions, and not standard available on Ethernet. A more generic solution has been developed as part of the “TSN”(Time Sensitive Networking) extensions, according to the (new) IEEE standards IEEE 802.3br and IEEE 802.1Qbu, popularly known as “Frame Preemption”.
Below, we will first describe the basics of frame preemption, followed by a more detailed explanation about the internals.
Cyclic communication
In industrial networks, it is very often seen that the application software runs in a cycle; the same code is executed again and again. The cycle times are usually in the order of milliseconds, but this can also be in the microsecond range for the applications with the highest demands regarding handling of events, accuracy, or output.

Figure 2: Real-time applications continuously execute the same cycle, both in software as on the network they use.
Every cycle the same processing is done: get all current inputs (digital, analogue, encoders, servo’s, camera’s, etc.), run the application software, set all outputs to their new values (digital, analogue, HMI’s, servo’s, etc.). This cyclic way of working is typical for PLC’s (Programmable Logic Controllers) and DCS’s (Distributed Control Systems), but also often seen in real-time applications.
The cycle time is constant. This allows the software to respond in time to any external events: in the same cycle, or perhaps the next. So when the cycle time is exceeded, timely response to external events cannot be guaranteed, and this is often a reason to alert the operator.
Communication is done via the network to the subordinate devices, and they must respond as quickly as possible. What happens on the network is completely predictable: the number of devices is known and the amount of data per device too Thus, what happens on the network is quite boring: always the same, the whole day: read inputs from device #1, read inputs from device #2, read inputs from device #3, etc. and at the end of the cycle: set outputs on device #1, set outputs on device #2, etc. Given the fixed number of devices and fixed I/O, it can be calculated in advance how much bits are transferred. Give the bitrate, it can also be calculated how long all transmissions are going to take (figure 3).
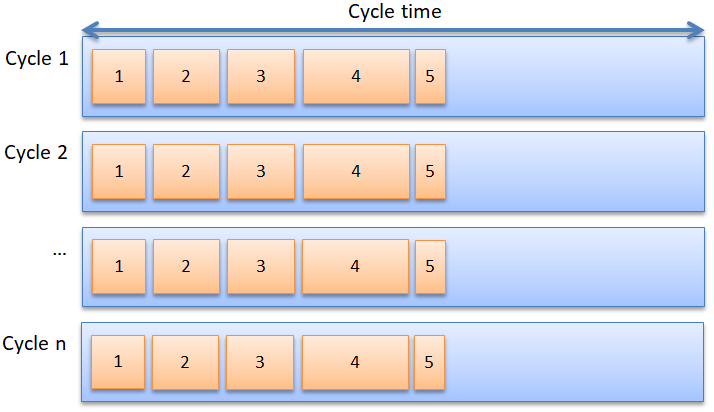
Figure 3: Cyclic transfer of 5 messages always takes the same time, every cycle.
So, we can calculate in advance how much time is needed for the network communication. Confusingly, this is also called “cycle time”. Ideally, this network cycle time is shorter than the cycle time for the software, so it is not delayed by the network.
In practice, the application software and the network run in parallel: while the software is running with data from network cycle ‘n’, the network is collecting data for cycle ‘n+1’. Even then, the network must be ready before the application software wants to start its next cycle.
Most existing industrial networks, both of the 1st generation (i.e., Profibus, Interbus, CAN, DeviceNet) and of the 2nd generation (Profinet, EtherCAT, etc.) function this way.
Acyclic data
Apart from the cyclic communication done on a network there is often a need for acyclic network messages. These are messages that come at (for the network) unexpected moments, for example due to the operator giving special commands (“Stop!”), because an error occurs somewhere, because diagnostic data is retrieved, because data must be downloaded, a webpage being read from a devices server, or any sort of communication over the network (even network managers starting a backup on a production network L). There must be some room for extra messages (figure 4) – not too much, otherwise the network cycle becomes too long and the application software must wait.

Figure 4: Two network cycles, each showing the same number of cyclic messages with the same amount of data. In both cycles one acyclic message (A1, A2) is sent, with different data.
The extra time allotted may also not be too short, otherwise long network messages cannot be completely transmitted within the available time. One solution is to allow for one full-length Ethernet message. Simple as it sounds, it has one drawback: a full-length Ethernet message can contain 1500 bytes of data, which is a huge amount compared to the usually small messages used for cyclic data – and, if there is no acyclic data, the network is doing nothing for the duration of one full-length Ethernet message. Additionally, is it guaranteed that there will be only one acyclic message? Or can there be more?
In any case, if there is too much acyclic traffic to fit in a cycle, the next cycle will suffer – its cyclic data is transmitted too late (figure 5). They must wait for message A3 to be finished (FIFO).

Figure 5: A too long acyclic message exceeds the time allotted to cycle 1. The cyclic messages in cycle 2 are transmitted too late.
What happens next depends on the application software. Did it miss important signals? Is equipment going to be damaged? Is production delayed? Can people get hurt?
Guard band
To prevent that too long or too many acyclic messages extend the cycle time, the “guard band” is used. It is a (configurable) period of time at the end of each cycle. Transmission of a network message may only start when it is guaranteed that it finishes in the guard band (= before the end of the cycle).
The next cycle can thus always start at the expected moment. If there are network messages that could not be transmitted in the previous cycle, they can now be transmitted (time allowing).
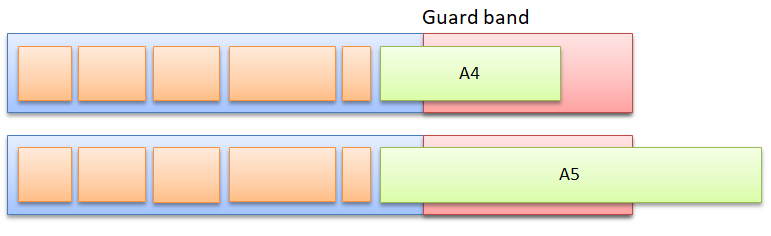
Figure 6: A message may only be transmitted if it finishes in the guard band. A4 complies to this rule, but A5 may not be transmitted.
Figure 6 (top) shows the transmission of only one acyclic message A4. But there is still time left in the guard band, so more messages may follow (if there are any). If there are none, the time is still wasted. So the network manager will tend to make the guard band as short as possible, but this may give a problem: too long messages (A5) cannot be transmitted anymore, they never fit! (figure 6 bottom). This is especially troublesome in protocols where the application / user has no control over the size of network messages, such as in TCP/IP.
So the guard band solves one problem, but there is still one to go: how to handle very long messages. It is this issue which “frame preemption” is going to solve for us. Its functionality is specified in IEEE 802.3br. The document can be requested from the IEEE for free. With a size of only 58 pages it is not too large, but you must know something about Ethernet in order to understand it well. The interesting part about the functional way-of-working start at page 38 in section 99.3 (which we will discuss below).
Express messages
Before we continue with the detailed explanation of the inner working of Ethernet frame preemption, we must first agree on the terminology. The real-time messages that are sent first in a cycle are called the “Express” messages. They are never subject to preemption. All other messages (called acyclic above), are called “Normal” messages. If they do not fit in the guard band, they are subject to preemption.
Frame preemption
This (for Ethernet) new technique solves the problem of a too long network message which doesn’t fit in a cycle. Simply explained, it does the following:
- Stop (preempt) the transmission of too long messages before the end of the guard band.
- Continue the transmission of the remainder of the message in the next cycle, following the express messages.
In Ethernet terminology, the preempted message is sent in multiple (>= 2) fragments. At the receiver, the fragments are assembled again to re-create (a copy of) the original network message.
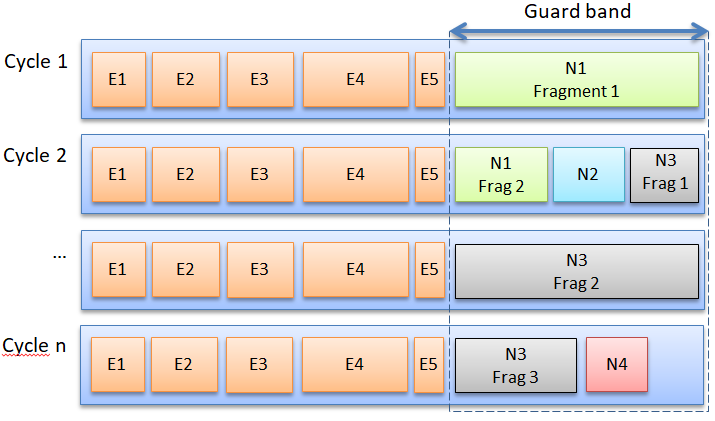
Figure 7: A too long message N1 is transmitted in fragments over multiple cycles. As long as there is time in the guard band, additional messages may be sent too (N2, N3, N4). If they don’t fit they are fragmented too, etc.
In figure 7, message N1 is too long to be completely transmitted in the guard band of cycle 1. It is thus preempted. After the transmission of this first fragment is stopped, the next cycle 2 can start at the expected moment. When the express messages have been transmitted, transmission of the second fragment of N1 is done. As there is still time in the guard band available, N2 can be transmitted too. With still time left, the first fragment of N3 can be transmitted. This is such a long message that even in the next cycle it cannot be completely transmitted, so it is preempted again, and the third fragment is sent in cycle 3. With enough time available, N4 can be transmitted. With nothing else to do, the line is silent for the remainder of the guard band.
For the receiving software, the fragmentation of messages is completely invisible. N1 is passed on to higher protocol levels only when the second fragment is completely received; identically so for message N3 after reception of the third fragment. So, for higher protocol levels it looks like any other Ethernet message. That the total transmission time is a little bit longer is unnoticeable; the message could as well have been sent a little later.
Error handling
What happens when the data in a fragment is corrupted while in-transit? The receiver detects this with a CRC which is appended to each fragment. Corrupted fragments are summarily discarded, just as any normal Ethernet message with corrupted data. But discarding a fragment means that (even when all other fragments are received without errors) the original Ethernet message cannot be re-created, so the message is completely lost.
The frame preemption algorithm does not perform any error recovery, unlike TCP/IP which can detect missing fragments in a data stream. But that is at a higher protocol level, which has more intelligence, RAM and CPU power. Adding such a capability to a frame preemption implementation would unnecessarily make it more complex, error-prone and slow.
So the frame preemption algorithm just follows the “I’ve tried it and it didn’t work out; so now it’s your problem” way of working, also called “Best Effort” in Ethernet jargon. Or: let higher protocol-levels detect and handle the missing message(s).
Backwards compatibility
Most Ethernet devices will never support frame preemption, as it is very specific for real-time applications. But how does a device with support for frame preemption communicate with a device that doesn’t? Simply: without frame preemption being used. The device with frame preemption capabilities asks the other device whether it supports it (via a special negotiation message). Because the other device doesn’t support it, it doesn’t understand it, so no answer comes back, and so it is decided not to use the frame preemption feature.
If it so happens that the other device does support frame preemption, it will say so, and the new feature can be used. Both devices (at both ends of the cable) must ask the other, so usually both parties will use frame preemption, but it is also possible that only one device does so (however unlikely). This is not a problem for Ethernet, because it is a full-duplex technology.
Note that on a switch frame preemption usage can thus be different for each port.
Rob Hulsebos has been active in industrial networks and cybersecurity for more than 30 years.